前言
最近有个非常奇怪的需求,我想让一段代码只被运行一次,但是又不想借助内核自带的 init 系列宏,因为这段代码的运行需要特殊的“上下文”环境。
单纯实现这样的操作很简单,随便弄个布尔变量把对应的代码包住就好了:
// 外层方法可能被多次调用
void foo(void)
{
static bool done = false;
if (!done) {
done = true;
// 在这里运行你只想要运行一次的东西
run_single_time();
}
}
void run_single_time(void)
{
}(别被放在方法里的 static bool 迷惑了,它不是一个局部变量,而是一个 static local variable ,更像一个全局变量)
但是,这种操作并不是 smp-safe 的。想象一下:假如两个 CPU 同时运行这段代码,那么 !done 是不是可能同时在两个 CPU 上成立,于是 run_single_time() 就可能在不同的 CPU 上被调用两次。更何况,即使两个 CPU 先后运行了这段代码,缓存一致性问题也可能导致目标代码被运行两次。很明显,这不是设计目标。
传统的实现
正常来说,很容易想到 run_single_time() 其实是一个临界区,因为无论如何都只能有一个 CPU 在运行其中的代码。
于是,顺理成章的就会想到使用 spin lock 来保护整个临界区:
DEFINE_SPINLOCK(foo_lock);
// 外层方法可能被多次调用
void foo(void)
{
static bool done = false;
spin_lock(&foo_lock);
if (!done) {
done = true;
// 在这里运行你只想要运行一次的东西
run_single_time();
}
spin_unlock(&foo_lock);
}
void run_single_time(void)
{
}借助 spin lock ,我们在解决并发问题的同时还利用其自带的内存屏障顺带解决了缓存一致性问题。
但是,只是为了保护这一个变量而使用 spin lock ,开销是否会太高了呢?。所以,有没有什么 lock-free 的实现方式呢?
借助 atomic
说到 lock-free 自然而然的就会想到 atomic operations 。
atomic operations 即原子操作,在执行原子操作时没有其它线程能够修改共享资源,从而避开了上面所描述的竞争问题。
现代处理器往往会提供专门的指令来实现原子操作,这也就意味着对于上面的那种单变量情况,原子操作比 spin lock 具有更高的效率。
以 ARM 为例,其提供了如 LDREX、STREX 指令来专门实现原子操作,在 ARMv8.1+ 指令集上更是提供了可选的 LSE 系列指令,进一步提高原子操作的性能。
比如我手里的骁龙 865 平台,就是支持 LSE 指令的,其原子操作也会采用 LSE 指令进行实现:
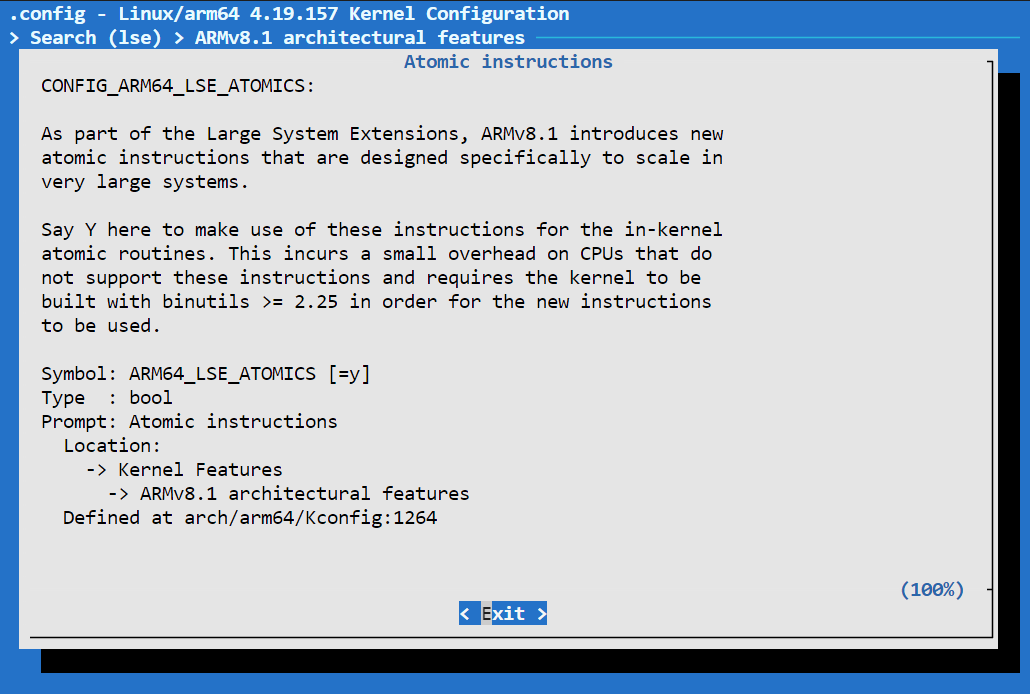
那么,该如何借助 atomic 实现“单次运行”呢?
很显然,像这样的简单替换成 atomic 是不行的:
// 外层方法可能被多次调用
void foo(void)
{
static atomic_t done = ATOMIC_INIT(0);
if (!atomic_read(&done)) {
atomic_set(&done, 1);
// 在这里运行你只想要运行一次的东西
run_single_time();
}
}
void run_single_time(void)
{
}这样能够解决的只有缓存一致性问题,多个 CPU 仍然可能同时执行完 atomic_read() ,然后同时进入临界区。
只有确保 read + set 的整个过程都是原子的,才能对临界区真正的起到保护作用。
这时,我们就需要使用 atomic api 提供的组合操作:
// 外层方法可能被多次调用
void foo(void)
{
static atomic_t done = ATOMIC_INIT(0);
// 它返回的是 increment 之后的值
if (atomic_inc_return(&done) == 1) {
// 在这里运行你只想要运行一次的东西
run_single_time();
}
}
void run_single_time(void)
{
}在这里,我们使用 atomic_inc_return() 来原子的实现 +1 与读取,这整个过程都是不可打断的,因此上面所说的“同时进入临界区”的问题也将不复存在——即,在某个 CPU 上,要么进行了 +1 和读取,要么完全没有进行 +1 和读取,不存在上面的那种读取了却没有写入的状态。
你可能会怀疑,假如 foo() 被频繁执行,是否存在溢出的风险?
嗯,这种风险确实是存在的,不过我们还可以使用 atomic_fetch_add_unless() api。
// 外层方法可能被多次调用
void foo(void)
{
static atomic_t done = ATOMIC_INIT(0);
// 它返回的是 add 之前的值
if (!atomic_fetch_add_unless(&done, 1, 1)) {
// 在这里运行你只想要运行一次的东西
run_single_time();
}
}
void run_single_time(void)
{
}这样,当 done 的值达到 1 时,add 操作将不再进行,溢出也就被解决掉了。
事实上,在现代处理器上,读/写指令往往本身就已经是原子的了,它们可以在一个时钟周期内完成,是不可再拆分的。因此,如果你使用了 atomic api ,但是只使用了 atomic_read() 和 atomic_write() 却没有使用任何组合操作,那就该怀疑一下在你的用例下是否真的需要 atomic 了,或许 READ_ONCE() 和 WRITE_ONCE() 反倒是更好的选择?
这么多奇怪的组合 atomic 操作,都是怎么实现的?
在不同的体系结构下,它们的实现方式可能是不一样的。
以 atomic_fetch_add_unless 为例,ARMv7 就有自己采用汇编进行的实现:
arch/arm/include/asm/atomic.h
static inline int atomic_fetch_add_unless(atomic_t *v, int a, int u)
{
int oldval, newval;
unsigned long tmp;
smp_mb();
prefetchw(&v->counter);
__asm__ __volatile__ ("@ atomic_add_unless\n"
"1: ldrex %0, [%4]\n"
" teq %0, %5\n"
" beq 2f\n"
" add %1, %0, %6\n"
" strex %2, %1, [%4]\n"
" teq %2, #0\n"
" bne 1b\n"
"2:"
: "=&r" (oldval), "=&r" (newval), "=&r" (tmp), "+Qo" (v->counter)
: "r" (&v->counter), "r" (u), "r" (a)
: "cc");
if (oldval != u)
smp_mb();
return oldval;
}
#define atomic_fetch_add_unless atomic_fetch_add_unless而对于 ARM64 ,我没有找到相关的实现,于是它大概率会 fallback 到内核自带的一份实现:
include/linux/atomic.h
/**
* atomic_fetch_add_unless - add unless the number is already a given value
* @v: pointer of type atomic_t
* @a: the amount to add to v...
* @u: ...unless v is equal to u.
*
* Atomically adds @a to @v, if @v was not already @u.
* Returns the original value of @v.
*/
#ifndef atomic_fetch_add_unless
static inline int atomic_fetch_add_unless(atomic_t *v, int a, int u)
{
int c = atomic_read(v);
do {
if (unlikely(c == u))
break;
} while (!atomic_try_cmpxchg(v, &c, c + a));
return c;
}
#endif这自带的实现其实挺有意思的,它基于经典的 compare-and-swap (CAS) 思想,这里就不展开了。
atomic 比上锁更高效?
在上面,我提及了 这也就意味着对于上面的那种单变量情况,原子操作比 spin lock 具有更高的效率 。
我把范围限制在了“单变量情况”,因为 atomic 虽然有硬件指令实现,但并不是没有争用的。以 ARM64 为例,在遭遇对共享内存区域的争用时,atomic store 指令会失败且需要重试,这种重试本质上就是一种忙等待,和 spin lock 原地自旋并没有本质上的区别。而且,为了保证缓存一致性,每执行一次 atomic 操作都需要刷新缓存,这也会造成额外的性能开销。
想象一下这样一种情况:你有一百个 int 需要保护,这一百个 int 在同一个函数中被不同线程读写。此时你可以选择将这一百个 int 全部转为 atomic_t ,你也可以选择使用一个 spin lock 来保护它们全部。
很显然,使用一个 spin lock 保护住这一个函数会更加高效,因为采用 atomic_t 反而会带来百倍的征用量,还需要反复刷新缓存。
由此可见,该如何在 atomic 和 spin lock 之间进行选择,完全取决于你的上下文环境,lock-free 不一定总是带来性能提升。
参考资料
https://stackoverflow.com/questions/75597629/is-lock-free-synchronization-always-superior-to-synchronization-using-locks
https://zhuanlan.zhihu.com/p/89299392