前言
这篇文章主要记录我对 Android 存储系统结构的一些理解,不限于回答以下几个问题:
- SDCardFS 是如何工作的?
- FUSE 又是如何工作的?
- FUSE 和 SDCardFS 有什么区别?它们是相互替代的关系吗?为什么要弃用 SDCardFS?
- “分区存储” 是怎么做到的?
- 多用户下是如何做到隔离 /sdcard 的?
文章基于 Android 12L。
文章将尽可能以我最舒适的姿势撰写,因此会夹杂一些推断与直觉(如有不准确的地方还望包容和指正)。
铺垫
别的一些文章
如果你对这些东西没有了解,那建议还是看看,因为下面会用到。
Emulated storage
Emulated storage 即 “模拟存储”,我们常见的 /storage/emulated 就是它。至于为什么有这个东西,得从历史讲起。
在 Android 2.x 时代,由于成本和技术限制,Android 手机往往需要插入一张外置 sd 卡作为 “媒体区”(/sdcard) (1)。由于这张 sd 卡常常需要在手机插入电脑时重新挂载到 windows 上以方便数据拷贝,因此它多采用 FAT32 格式。这种格式与手机内置存储的格式是不同的(2) :它对大小写不敏感,也不支持 Unix 文件权限。
- (1) 那时没插 sd 卡手机也能正常运行,只是没法保存图片之类的,微信里看照片都是黑框框。
- (2) 旧时代的内置存储往往采用 ext4 格式,近些年来被 f2fs 逐步取代。这里的内置存储是指
/data区。
随着技术的进步和对性能需求的提升,手机开始有了足够的容量将这张外置 sd 卡整合进内置存储。那么问题来了,我该如何分配手机的空间?还是像原来那样独立的分一个分区给 sd 卡吗?那要分多大?这样空间利用率岂不是贼差?很显然,独立的分一个分区出来是不实用的。Android 采用的方案是将原本的外置 sd 卡整体塞进 /data 里,放在 /data/media,再经过一些处理将其映射到原来的 /sdcard。之所以要经过处理,是因为 /data/media 目录是受 Unix 文件权限保护的,直接映射(比如 bind mount )轻则 Permission denied ,重则应用利用自己的 uid、gid 在里面瓜分领地,互设屏障。这和原来共享的外置 sd 卡就完全不同了。除此之外,内置存储是文件系统往往是区分大小写的,这也和原来的外置 sd 卡不同。为了兼容性,我们必须对这个映射过程进行处理,使它表现的就和原来的 FAT32 一样。这便是 "Emulated"。
随着 Android 版本的迭代,"Emulated" 的实现方式也发生着变化。在较早的 Android 版本上其采用 FUSE 实现,在 Android O 上谷歌采用性能更好的 SDCardFS 取代了 FUSE ,而在 Android 11 上他又改了回去,SDCardFS 惨遭弃用。在这篇文章中我不打算考古,故不会去研究上古时期是如何使用 FUSE 的。我们会从 SDCardFS 开始来看看它的工作机制,再看看能不能为谷歌在 Android 11 切回 FUSE 找到一些正当理由。
SDCardFS
简介
SDCardFS 是一个纯内核侧的驱动,它的大多数配置只能在 mount 时设置好,不能动态调整。正因如此,它与用户空间的交互更少,具有更好的性能(1)。
- (1) 相对于 FUSE 而言,FUSE 将在后面再介绍。
SDCardFS 所做的工作,概括一下就是“处理”和“转发”,又或者说就是上面的“模拟”。
“处理”是按上面所说,尽可能让它看起来像一个 FAT32 文件系统。
“转发”便是将用户(“上层”)在其上的操作转交给“下层文件系统”,在 “模拟存储” 中也就是转交给 /data/media 。下面的内容主要关注“处理”,“转发”实在是有点乏味。
SDCardFS 的挂载由 vold 发起,vold 会 fork() 出一个子进程来运行一个名为 sdcard 的可执行文件,而它所做的事情便是调用 mount wrapper ,按照预定义的挂载点位置挂载 SDCardFS ,并传入对应的挂载参数。
接下来,我将介绍几个重要的挂载参数并看看它们的功能,然后再看看它们是如何与 Android 系统相配合使用的。
挂载参数
这里只挑几个我认为重要且与系统配合密切的参数进行介绍,剩下的请自行 READ THE FUCKING SOURCE CODE 。
重要的挂载参数包括:fsuid=<>、fsgid=<>、gid=<>、mask=<> (1) 等。
- (1)
<>代表填入配置内容,比如gid=9997。
gid
这个参数代表了从 “上层”(1) 视角看到和被验证的,文件或文件夹的组号。
SDCardFS 可以覆盖 “下层”(2) 文件系统的文件所有者信息(3),向“上层”汇报并使用特定的文件所有者信息。
这就解决了上面提及的 Unix 文件权限问题中的所有者问题,应用不再能够利用文件所有者信息来互设访问门槛,因为这些所有者信息最终会被 SDCardFS 覆写。
- (1) “上层” 指通过 SDCardFS 挂载点访问的进程。比如应用访问 emulated storage 时,应用就是这里的“上层”。
- (2) “下层” 指真正存储数据的地方,也就是上面所说的“转发”的目的地。
- (3) 这里的“所有者”包含 owner + group 。
从代码角度看看:
kernel/fs/sdcardfs/inode.c
static int sdcardfs_permission(struct vfsmount *mnt, struct inode *inode, int mask)
{
......
copy_attrs(&tmp, inode);
tmp.i_uid = make_kuid(&init_user_ns, top->d_uid);
tmp.i_gid = make_kgid(&init_user_ns, get_gid(mnt, inode->i_sb, top));
......
}kernel/fs/sdcardfs/sdcardfs.h
static inline int get_gid(struct vfsmount *mnt,
struct super_block *sb,
struct sdcardfs_inode_data *data)
{
struct sdcardfs_vfsmount_options *vfsopts = mnt->data;
......
return multiuser_get_uid(data->userid, vfsopts->gid);
}这里只列出权限检查中的一处示意一下,还有汇报权限之类的这里就不举例了。
从上方代码中可以看到,对上层只有 gid 是可自行配置的,其存储在 sdcardfs_vfsmount_options 结构体的 gid 中。
fsuid、fsgid
这俩代表了非特殊文件 / 文件夹要以何种所有者和组身份在“下层”文件系统上存储。
至于为什么要以特定身份存储,我想首先是为了整齐,然后也为系统中的部分服务保留了访问的权限吧。
从代码角度看看:
kernel/fs/sdcardfs/inode.c
const struct cred *override_fsids(struct sdcardfs_sb_info *sbi,
struct sdcardfs_inode_data *data)
{
struct cred *cred;
const struct cred *old_cred;
uid_t uid;
cred = prepare_creds();
if (!cred)
return NULL;
if (sbi->options.gid_derivation) {
if (data->under_obb)
uid = AID_MEDIA_OBB;
else
uid = multiuser_get_uid(data->userid, sbi->options.fs_low_uid);
} else {
uid = sbi->options.fs_low_uid;
}
cred->fsuid = make_kuid(&init_user_ns, uid);
cred->fsgid = make_kgid(&init_user_ns, sbi->options.fs_low_gid);
old_cred = override_creds(cred);
return old_cred;
}可以看到,对下层使用的 uid 和 gid 分别存储在 sdcardfs_mount_options 结构体的 fs_low_uid 与 fs_low_gid 中。
上面的方法进行的是对调用者进程 credential 的修改。这种修改有点 Binder.clearCallingIdentity() 内味儿,只不过它所给以的身份是预定义的。于是内核态的进程就继续拿着预定义的身份向下访问“下层”文件系统,顺理成章的,“下层”文件系统中留下的 uid 和 gid 也就是预定义的了。和 Binder 类似,SDCardFS 在完成这一操作后也会通过 revert_fsids(saved_cred); 来还原进程本身具有的 uid 和 gid ,从而避免被提权。
SDCardFS 在一批 inode_operations (如 mkdir、create、setattr)中进行了上述 替换 + 下层访问 + 还原 的操作,从而实现了以特定所有者和组身份在“下层”文件系统上存储文件。
mask
这个玩意儿,主要起到的是对“上层”覆盖权限的作用,即使得从“上层”视角看到和被验证的是经过处理的权限。上面 gid 的作用方向也是“上层”,但是它的作用对象是单纯的组号,而 mask 的作用对象便是“权限”本身。
康康代码:
kernel/fs/sdcardfs/sdcardfs.h
static inline int get_mode(struct vfsmount *mnt,
struct sdcardfs_inode_info *info,
struct sdcardfs_inode_data *data)
{
int owner_mode;
int filtered_mode;
struct sdcardfs_vfsmount_options *opts = mnt->data;
int visible_mode = 0775 & ~opts->mask;
if (data->perm == PERM_PRE_ROOT) {
/* Top of multi-user view should always be visible to ensure
* secondary users can traverse inside.
*/
visible_mode = 0711;
} else if (data->under_android) {
/* Block "other" access to Android directories, since only apps
* belonging to a specific user should be in there; we still
* leave +x open for the default view.
*/
if (opts->gid == AID_SDCARD_RW)
visible_mode = visible_mode & ~0006;
else
visible_mode = visible_mode & ~0007;
}
owner_mode = info->lower_inode->i_mode & 0700;
filtered_mode = visible_mode & (owner_mode | (owner_mode >> 3) | (owner_mode >> 6));
return filtered_mode;
}mask 存储在 sdcardfs_vfsmount_options 结构体的 mask 成员变量中。
可以看到,它是作为掩码存在,掩去对应的权限位从而使“上层”进程失去对应的访问权限。
一般的权限处理过程是这样的:预设一个最高权限,这里是 775 ,然后应用 mask 掩去对应的权限,比如 mask 为 007 时,得到的“可见权限”就是 750 。然后“可见权限”会和“下层”文件系统上的 owner 权限取与(说白了就是哪个权限最低取哪个),得到最终要展示给“上层”的权限。比如文件在“下层”文件系统上的权限是 600 ,因为它是和 owner 权限取与,所以相当于要计算 750 & 666 ,得到的自然是 640 ,而这也是最终展示给“上层”的权限。
- 需要注意的是,上面的权限数字都是八进制的形式。在 C 语言中,0 开头表示的数字都是八进制,这就是为什么上面的代码中的权限均是 0 开头的。但是,采用
mask=<>挂载参数传入的权限是十进制的形式,因此还要进行一个换算。
可能有点复杂,但,不管咋样,mask 就是用来给权限“降级”的,从而施加更加严格的访问控制。
忽略大小写
嗯,这不是什么复杂的东西,SDCardFS 中有几个内联函数专门负责这项功能:
kernel/fs/sdcardfs/sdcardfs.h
static inline bool str_case_eq(const char *s1, const char *s2)
{
return !strcasecmp(s1, s2);
}
static inline bool str_n_case_eq(const char *s1, const char *s2, size_t len)
{
return !strncasecmp(s1, s2, len);
}
static inline bool qstr_case_eq(const struct qstr *q1, const struct qstr *q2)
{
return q1->len == q2->len && str_n_case_eq(q1->name, q2->name, q2->len);
}凡是遇到比较 dentry->d_name(文件/目录名) 的,都进来用这个判断就好啦。
与系统相配合
这一块内容,主要讲述 SDCardFS 是如何与系统相配合从而实现权限控制的。
由于 SDCardFS 已经 legacy 再加上我懒得去研究历史,因此下面的内容存在一定的瞎猜成分。
铺垫:应用所在组
从上面可以看到,我们可以在挂载 SDCardFS 时通过传入参数 gid=<> 来为“上层”使用特定的组号。但是,这有什么用吗?“上层”得首先具有这个 gid 才能拥有操作的权限诶。但是应用的 gid 不是由系统分配的吗,不同应用甚至会被分到不同的 gid,那该如何统一的管理权限呢?
于是 Android 复用了 Linux 内核的 groups (supplementary groups)机制(1) ,属于同一 用户(2) 的应用进程会被加入到对应用户的 EVERYBODY 组中:
services/core/java/com/android/server/am/ProcessList.java
private int[] computeGidsForProcess(int mountExternal, int uid, int[] permGids,
boolean externalStorageAccess) {
ArrayList<Integer> gidList = new ArrayList<>(permGids.length + 5);
......
final int userGid = UserHandle.getUserGid(UserHandle.getUserId(uid));
......
if (userGid != UserHandle.ERR_GID) {
gidList.add(userGid);
}
......
}上面的 UserHandle.getUserGid() 会返回对应用户的 EVERYBODY 组号。
既然一个用户下的所有进程都具有一个相同的 group ,那么,我们只要传入 gid=<这个组号> 就可以授予一批应用访问权限了。
至于这个机制的应用,会在下一小节内容中提及。
- (1) 详见上面的铺垫文章,里面有对其应用的更多举例。
- (2) 这里的“用户”是指 Android 的多用户机制,而非上面的 uid 。
权限与多视图
自从 Android 6.0 以来,Android 开始引入了动态权限系统(运行时权限):用户可以在应用运行时,通过授权弹窗,动态的授予应用对外部存储的访问权限。
这也就意味着,不同的应用需要具有不同的外部存储视图:对于没有权限的应用,/sdcard/Android 下的应用包名文件夹应该是随时可以读写的;对于有读权限的应用,在上一条的基础上加上对其它文件的读取权限;对于有写权限的应用,在上一条的基础上再加上写权限。
但是,SDCardFS 作为纯内核侧的驱动,并不能实时与系统服务通信去了解应用的授权状态。因此,Android 采用了将 SDCardFS 挂载多次的方式来提供不同的视图:
system/core/sdcard/sdcard.cpp
static void run_sdcardfs(const std::string& source_path, const std::string& label, uid_t uid,
gid_t gid, userid_t userid, bool multi_user, bool full_write,
bool derive_gid, bool default_normal, bool unshared_obb, bool use_esdfs) {
std::string dest_path_default = "/mnt/runtime/default/" + label;
std::string dest_path_read = "/mnt/runtime/read/" + label;
std::string dest_path_write = "/mnt/runtime/write/" + label;
std::string dest_path_full = "/mnt/runtime/full/" + label;
......
if (multi_user) {
// Multi-user storage is fully isolated per user, so "other"
// permissions are completely masked off.
if (!sdcardfs_setup(source_path, dest_path_default, uid, gid, multi_user, userid,
AID_SDCARD_RW, 0006, derive_gid, default_normal, unshared_obb,
use_esdfs) ||
!sdcardfs_setup_secondary(dest_path_default, source_path, dest_path_read, uid, gid,
multi_user, userid, AID_EVERYBODY, 0027, derive_gid,
default_normal, unshared_obb, use_esdfs) ||
!sdcardfs_setup_secondary(dest_path_default, source_path, dest_path_write, uid, gid,
multi_user, userid, AID_EVERYBODY, full_write ? 0007 : 0027,
derive_gid, default_normal, unshared_obb, use_esdfs) ||
!sdcardfs_setup_secondary(dest_path_default, source_path, dest_path_full, uid, gid,
multi_user, userid, AID_EVERYBODY, 0007, derive_gid,
default_normal, unshared_obb, use_esdfs)) {
LOG(FATAL) << "failed to sdcardfs_setup";
}
} ......
}几个挂载点按照以下策略进行挂载(1):
/mnt/runtime/default/emulated采用gid=<AID_SDCARD_RW>,mask=<0006>挂载。/mnt/runtime/read/emulated采用gid=<AID_EVERYBODY>,mask=<0027>挂载。/mnt/runtime/write/emulated采用gid=<AID_EVERYBODY>,mask=<0007>挂载。- 还有个 full,挂载策略和 write 相同,此处不再介绍。
每个应用都运行在自己的“挂载命名空间”中,Android 会根据“动态权限”的授权状况,在对应的“挂载命名空间”中 bind mount 上述挂载点:
- 没有权限:
/mnt/runtime/default/emulated->/storage/emulated。 - 有读权限(READ_EXTERNAL_STORAGE):
/mnt/runtime/read/emulated->/storage/emulated。 - 有写权限(WRITE_EXTERNAL_STORAGE):
/mnt/runtime/write/emulated->/storage/emulated。
/storage/emulated/<用户号>(2) 会被 symlink 到 /storage/self/primary,然后再被 symlink 到 /sdcard ,从而成为我们熟悉的外置存储(3)。
- (1) 这里面的
<xxx>不代表实际传入挂载参数的值。gid传入的是组号,上面以组名示意。mask传入的是十进制形式,上面的是八进制,还需要进行一次转换。 - (2) 关于这个
<用户号>,会在后面介绍多用户机制的时候再提及。 - (3) 没有具体考证在旧版 Android 系统上这条 symlink 路径是否仍然成立,仅供参考。
接下来看看上面的挂载参数是如何配合到权限控制的:
首先,对于具有读权限的应用,挂载参数中的 gid 为 EVERYBODY。经过上面的铺垫我们知道所有应用都属于对应的 EVERYBODY 组,因此所有应用都具有“组权限”。然后呢,根据 mask 我们可以看到,组的对应位是 2 ,也就是说写权限被掩去了,应用只具有读权限,这便与 Android 动态权限系统所给以的权限相吻合。
其次,对于具有写权限的应用,挂载参数中 gid 与上面的读权限是相同的,但是 mask 中组的对应位为 0 ,不再掩去任何东西。按照上面描述的权限计算方法可以得出此时应用是具有写入权限的,与系统的动态权限系统相吻合。
接下来是神奇的针对没有权限应用的 default ,其挂载参数中的 gid 是 SDCARD_RW ,一般的应用程序可不在这个组里面(1),自然也就拿不到组权限。那么问题来了,没有权限时应用被允许干啥?还记得上面的需求吗?即使没有请求存储权限,应用也是可以访问它们在 Android 目录下的包名文件夹的,那这是怎么做到的呢?
请看下一小节的内容 :)
另外,mask 中“其它”的对应位是 7 (2),也就是掩去了所有权限,也就是说不属于该用户的应用无权对该用户的文件进行访问(指 Android 多用户机制,这里只作提及,下面再介绍)。
- (1) 这个组里的东西往往是特权系统服务,比如 MTP 。
- (2)
虽然 default 的是 6 ,但是好像并没有卵用,按照我们上面的分析,执行权限要生效则下层源文件的所有者必须具有执行权限,但是创建的新文件默认并没有执行权限,而 SDCardFS 设置了 Inode Attributes 使得用户无法修改权限,我们压根就无法通过常规操作使一个文件具有执行权限。因此这个执行位是留给谁用的我暂且还蒙在鼓里。是给 Android 目录用的,至于有什么用,仍然蒙在鼓里...
针对 Android 目录的特殊处理
从上面的内容中可以知道,SDCardFS 还需要处理一个特别棘手的需求,那就是应用在没有存储权限时也需要能够访问自己在 Android 目录下对应的“包名目录”,那么,它是如何做到的呢?
概括一下,还是利用上面基于 uid、gid、groups 的文件系统访问控制。
SDCardFS 在执行 lookup() 建立 dentry 时,会调用 get_derived_permission_new() ,根据父目录的类型和子目录的名称,确定子目录的类型,并将其装进 sdcardfs inode 中:
kernel/fs/sdcardfs/derived_perm.c
void get_derived_permission_new(struct dentry *parent, struct dentry *dentry,
const struct qstr *name)
{
struct sdcardfs_inode_info *info = SDCARDFS_I(d_inode(dentry));
struct sdcardfs_inode_info *parent_info = SDCARDFS_I(d_inode(parent));
struct sdcardfs_inode_data *parent_data = parent_info->data;
appid_t appid;
unsigned long user_num;
int err;
struct qstr q_Android = QSTR_LITERAL("Android");
struct qstr q_data = QSTR_LITERAL("data");
struct qstr q_sandbox = QSTR_LITERAL("sandbox");
struct qstr q_obb = QSTR_LITERAL("obb");
struct qstr q_media = QSTR_LITERAL("media");
struct qstr q_cache = QSTR_LITERAL("cache");
/* By default, each inode inherits from its parent.
* the properties are maintained on its private fields
* because the inode attributes will be modified with that of
* its lower inode.
* These values are used by our custom permission call instead
* of using the inode permissions.
*/
inherit_derived_state(d_inode(parent), d_inode(dentry));
/* Files don't get special labels */
if (!S_ISDIR(d_inode(dentry)->i_mode)) {
set_top(info, parent_info);
return;
}
/* Derive custom permissions based on parent and current node */
switch (parent_data->perm) {
case PERM_INHERIT:
case PERM_ANDROID_PACKAGE_CACHE:
set_top(info, parent_info);
break;
case PERM_PRE_ROOT:
/* Legacy internal layout places users at top level */
info->data->perm = PERM_ROOT;
err = kstrtoul(name->name, 10, &user_num);
if (err)
info->data->userid = 0;
else
info->data->userid = user_num;
break;
case PERM_ROOT:
/* Assume masked off by default. */
if (qstr_case_eq(name, &q_Android)) {
/* App-specific directories inside; let anyone traverse */
info->data->perm = PERM_ANDROID;
info->data->under_android = true;
} else {
set_top(info, parent_info);
}
break;
case PERM_ANDROID:
if (qstr_case_eq(name, &q_data)) {
/* App-specific directories inside; let anyone traverse */
info->data->perm = PERM_ANDROID_DATA;
} else if (qstr_case_eq(name, &q_sandbox)) {
/* App-specific directories inside; let anyone traverse */
info->data->perm = PERM_ANDROID_DATA;
} else if (qstr_case_eq(name, &q_obb)) {
/* App-specific directories inside; let anyone traverse */
info->data->perm = PERM_ANDROID_OBB;
info->data->under_obb = true;
/* Single OBB directory is always shared */
} else if (qstr_case_eq(name, &q_media)) {
/* App-specific directories inside; let anyone traverse */
info->data->perm = PERM_ANDROID_MEDIA;
} else {
set_top(info, parent_info);
}
break;
case PERM_ANDROID_OBB:
case PERM_ANDROID_DATA:
case PERM_ANDROID_MEDIA:
info->data->perm = PERM_ANDROID_PACKAGE;
appid = get_appid(name->name);
if (appid != 0 && !is_excluded(name->name, parent_data->userid))
info->data->d_uid =
multiuser_get_uid(parent_data->userid, appid);
break;
case PERM_ANDROID_PACKAGE:
if (qstr_case_eq(name, &q_cache)) {
info->data->perm = PERM_ANDROID_PACKAGE_CACHE;
info->data->under_cache = true;
}
set_top(info, parent_info);
break;
}
}截取关键部分:
case PERM_ANDROID_OBB:
case PERM_ANDROID_DATA:
case PERM_ANDROID_MEDIA:
info->data->perm = PERM_ANDROID_PACKAGE;
appid = get_appid(name->name);
if (appid != 0 && !is_excluded(name->name, parent_data->userid))
info->data->d_uid =
multiuser_get_uid(parent_data->userid, appid);
break;当父目录是 Android/data、Android/obb 或 Android/media 时,也就是说,子目录是“包名目录”,此时子目录的名称(包名)会被塞给 get_appid() 转换为该应用的 uid ,然后被塞进 sdcardfs inode 中。于是,“包名目录”的 owner 就变成了该包名对应的应用的 uid ,那么这个应用就顺理成章的拥有了对自己“包名目录”的访问权限。
这个过程不能说非常 hacky ,只能说非常有针对性。。。
那么问题来了,SDCardFS 是一个纯内核侧的东西,它是怎么知道哪个包名对应的 uid 是多少的?我们在挂载的时候也没告诉它啊!
诶,那开个洞特地告诉它一下不就行了么?
kernel/fs/sdcardfs/Kconfig
config SDCARD_FS
tristate "sdcard file system"
depends on CONFIGFS_FS
default n
help
Sdcardfs is based on Wrapfs file system.毕竟,人家可是 depends on CONFIGFS_FS 的,随时已经准备好开洞了。
OnePlus8T:/ # ls /config/sdcardfs/
android com.android.providers.downloads
android.auto_generated_rro_vendor__ com.android.providers.downloads.ui
......OnePlus8T:/ # ls /config/sdcardfs/com.android.launcher3
appid clear_userid excluded_userids
OnePlus8T:/ # cat /config/sdcardfs/com.android.launcher3/appid
10100我们可以在 configfs 的挂载点 /config 下找到 SDCardFS 开的洞:/config/sdcardfs/ 下有一大堆以应用包名命名的目录,而每一个目录中又有名为 appid 的文件,应用的 uid(1) 就被这么硬生生的写了进去。。。
- (1) 其实这里写进去的东西叫做 appId ,但是对于用户 0 ,它与 uid 是基本等同的,参见“针对多用户的特殊处理”。
frameworks/base/services/core/java/com/android/server/pm/Settings.java
void writeKernelMappingLPr(String name, int appId, int[] excludedUserIds) {
KernelPackageState cur = mKernelMapping.get(name);
final boolean firstTime = cur == null;
final boolean userIdsChanged = firstTime
|| !Arrays.equals(excludedUserIds, cur.excludedUserIds);
// Package directory
final File dir = new File(mKernelMappingFilename, name);
if (firstTime) {
dir.mkdir();
// Create a new mapping state
cur = new KernelPackageState();
mKernelMapping.put(name, cur);
}
// If mapping is incorrect or non-existent, write the appid file
if (cur.appId != appId) {
final File appIdFile = new File(dir, "appid");
writeIntToFile(appIdFile, appId);
if (DEBUG_KERNEL) Slog.d(TAG, "Mapping " + name + " to " + appId);
}
......
}这一切,是由 PackageManagerService 直接负责的。
针对多用户的特殊处理
Android 本身自带了一个多用户机制。不同用户具有相互隔离的应用数据和“模拟存储”。很显然,SDCardFS 需要对此进行支持。
这里的“用户”并不是指上面的 uid ,而是一个 真正的 Android 用户 。不同用户可以安装不同的应用,而这些应用又具有对应的 uid 。
不同用户的“模拟存储”数据在“下层”文件系统上是以文件夹的方式分隔存储的,比如“主用户”(用户号为 0 )的数据存储在 /data/media/0 ,副用户(比如用户号为 10 )的数据存储在 /data/media/10 。
SDCardFS 并不会为多个用户进行多次挂载,它在被挂载时传入的是整个 /data/media 而非特定的用户目录。这意味着,SDCardFS 的“根目录”是一个有着一堆用户文件夹的“多用户视图”。
于是,在执行 lookup() 创建 dentry 时,SDCardFS 会调用 get_derived_permission_new() 根据其“根目录”的文件夹名,将用户号记录下来,并让它的子目录也继承这些数据。这便是它得知目前的操作对象位于哪个用户的方式。
kernel/fs/sdcardfs/derived_perm.c
void get_derived_permission_new(struct dentry *parent, struct dentry *dentry,
const struct qstr *name)
{
....
case PERM_PRE_ROOT:
/* Legacy internal layout places users at top level */
info->data->perm = PERM_ROOT;
err = kstrtoul(name->name, 10, &user_num);
if (err)
info->data->userid = 0;
else
info->data->userid = user_num;
break;
......
}那么,面对多用户,它需要做些什么呢?
不妨先看看 Android 本身需要些什么。
不同的应用一般具有不同的 uid ,这是众所周知的。那么,不同用户下的相同应用,它们的 uid 是相同的还是不同的呢?答案是不同,但是却有规律:
frameworks/base/core/java/android/os/UserHandle.java
/**
* @hide Range of uids allocated for a user.
*/
@UnsupportedAppUsage
public static final int PER_USER_RANGE = 100000;
......
/**
* Returns the uid that is composed from the userId and the appId.
* @hide
*/
@UnsupportedAppUsage
@TestApi
public static int getUid(@UserIdInt int userId, @AppIdInt int appId) {
if (MU_ENABLED) {
return userId * PER_USER_RANGE + (appId % PER_USER_RANGE);
} else {
return appId;
}
}我们可以在系统的框架中找到应用 uid 的计算方法。在多用户启用时,应用的 uid 等于 用户号 * 100000 + (应用 id % 100000) 。翻译一下,在一般情况下(指不溢出),对于用户 0 ,应用的 uid 等于 应用 id 。对于别的用户,则应用 uid 等于 用户号 * 100000 + 应用 id。
形象的看一下,有一个应用在用户 0 的 uid 为 10137 ,那么它在用户 10 的 uid 就将会是 1010137 ,在用户 11 的 uid 将会是 1110137 。这,可以被看作一种有规律的“偏移”。
所以 SDCardFS 也需要继承这一逻辑,为不同用户目录下的“包名文件夹”提供与用户号相对应的 uid ,从而正确授予用户应用访问权限。
我们可以轻易的在 SDCardFS 的代码中找到与上方框架逻辑相对应的 uid 计算方式:
kernel/fs/sdcardfs/multiuser.h
#define AID_USER_OFFSET 100000 /* offset for uid ranges for each user */
......
typedef uid_t userid_t;
typedef uid_t appid_t;
static inline uid_t multiuser_get_uid(userid_t user_id, appid_t app_id)
{
return (user_id * AID_USER_OFFSET) + (app_id % AID_USER_OFFSET);
}
......在最终计算“包名文件夹”的 uid 时,上述方法会被调用,从而根据用户进行“偏移”:
kernel/fs/sdcardfs/derived_perm.c
case PERM_ANDROID_OBB:
case PERM_ANDROID_DATA:
case PERM_ANDROID_MEDIA:
info->data->perm = PERM_ANDROID_PACKAGE;
appid = get_appid(name->name);
if (appid != 0 && !is_excluded(name->name, parent_data->userid))
info->data->d_uid =
multiuser_get_uid(parent_data->userid, appid);
break;于是,目标达成了,安装在不同用户下的应用即使使用着相同的 SDCardFS 挂载也能拿到正确的“包名文件夹” uid 。
别急,这只是处理了“包名文件夹”,但是针对拥有读/写权限应用,我们还有上面所提及的 EVERYBODY 组问题需要处理呢。
等等,还记得 EVERYBODY 组是干啥用的吗?可以向上翻一番 (●'◡'●) 。
那么,这个组是被不同用户中的应用中所共享的吗?
答案是否定的。
可以看到,在框架中,EVERYBODY 组对应的 gid 也会根据用户号进行“偏移”:
frameworks/base/core/java/android/os/UserHandle.java
/**
* Returns the gid shared between all apps with this userId.
* @hide
*/
public static int getUserGid(@UserIdInt int userId) {
return getUid(userId, Process.SHARED_USER_GID);
}“偏移”采用的算法和上面的 uid 是一致的,再看看 SDCardFS 是如何实现这一点的:
kernel/fs/sdcardfs/sdcardfs.h
static inline int get_gid(struct vfsmount *mnt,
struct super_block *sb,
struct sdcardfs_inode_data *data)
{
......
return multiuser_get_uid(data->userid, vfsopts->gid);
}Easy,调用上面所提到的 multiuser_get_uid() ,把作为挂载参数传进来的 gid 根据用户号进行“偏移”即可。
小结
对 SDCardFS 的浅析到此就结束了,可以看到,它虽然是一个内核侧的驱动,但是它与 Android 系统之间的耦合可一点也不浅,甚至有不少 hardcode 的 dirty 操作来适应系统的需求。那么,当需求继续增加的时候会发生什么呢?那就接着往下看吧。
FUSE
FUSE 是 Filesystem in Userspace 的简称,是所谓“运行在用户空间的文件系统”。
自从 Android 11 起,它又重新回到了我们的视线。
引入:变态需求
Android 11 对 Android 10 引入的“分区存储”机制进行了改进,效果(1) 是这样的:
- 在没有存储权限的情况下,应用也可以访问“模拟存储”,但是只能列出目录结构,看不到也不能访问一般目录下的一般文件。
- 在没有存储权限的情况下,应用可以自由的在 “媒体目录”(2) 下创建文件夹和媒体文件。
- 在没有存储权限的情况下,应用只能看到和访问自己在“媒体目录”下创建的媒体文件(3)。
- 在拥有
READ_EXTERNAL_STORAGE权限的情况下,应用可以看到 “媒体目录” 下别的应用创建的媒体文件。 - 即使拥有
READ_EXTERNAL_STORAGE权限,应用也看不到除媒体文件外的任何文件。 WRITE_EXTERNAL_STORAGE不再拥有任何效果。- 文件管理类应用转而使用
MANAGE_EXTERNAL_STORAGE权限,类似之前WRITE_EXTERNAL_STORAGE权限的效果。 - 非文件管理类应用,如有访问非媒体文件或非“媒体目录”的需求,必须采用 SAF 的实现(或者也可以让别的应用给你扔个
Uri)。 - 无论是否拥有
READ_EXTERNAL_STORAGE或MANAGE_EXTERNAL_STORAGE权限,应用都不再能够列出Android/data/和Android/obb/等目录,也无法访问其中非自己所属的文件夹(4)。 - 上述内容对一切文件操作方式均生效,无论是走 java 层或 native 层的文件 api ,还是优雅的使用
MediaStore。
注释:
- (1) 只针对 target api 达到要求的应用生效。
- (2) 指
MediaStoreapi 使用的保存目录,比如DCIM/、Pictures/、Download/等,具体参见 文档 。没错,“下载的文件”在这里姑且也被算作“媒体文件”了。 - (3) 只能访问“本次安装”中自己所创建的内容。卸载重装后,自己之前创建的也访问不了 ヾ(•ω•`)o 。
- (4) 目前仍然可以通过 SAF ,使用构造的 Uri 来绕过这一限制。
总结一下:“媒体目录”里无需任何权限即可随便拉屎,还可以通过在“媒体目录”中创建特殊名字的文件夹跨应用追踪用户(低成本 IPC 方案),甚至不需要请求任何权限。但没有权限只能看到自己创建的媒体可谓是非常的“沙箱”,非常的隐私。
再总结:拉屎成本降低,拉屎位置受限,吃屎十分困难(指偷窥其它应用创建的内容)。
那么问题来了,SDCardFS 还能通过继续改进来满足这些需求吗?想必这是十分困难的—— SDCardFS 的设计目标就是进行高效的纯内核态“转发”,但是对于上述需求,有太多依赖于用户态的东西了,几乎每一次访问都需要根据访问者身份和访问对象的具体情况来确定权限,而这些数据又无法直接被记录在下层文件系统中,频繁的内核态——用户态交互是避免不的了。
于是,FUSE 它回来了。
简介
在这里,先概述一下 FUSE 的工作方式。
FUSE 由两部分组成:内核侧的驱动和用户侧的“守护进程”。内核侧的 FUSE 驱动同样是一个“转发器”,但与 SDCardFS 不同的是,它不会将请求直接转发给“下层文件系统”(1) ,而是会将请求转发给位于用户空间的“守护进程”。守护进程在执行完相关操作后(比如鉴权、访问“下层文件系统”取得结果),再将结果返回给内核侧的驱动,最后内核侧的驱动将结果返回给发起请求的进程。
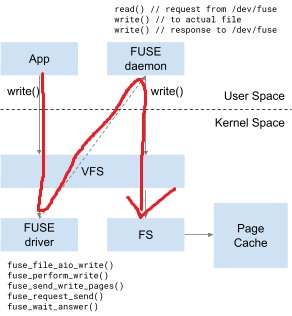
借用你谷在文档里放的图,一次基于 FUSE 的“模拟存储”访问就是这样一个歪七扭八的过程。
可以发现:
- 对下层文件系统的访问是由用户空间的“守护进程”完成的。
- 整个过程实际上进行了两次文件请求:第一次由“应用程序”发起,由内核侧的 FUSE 驱动处理;第二次由 FUSE “守护进程”发起,由“下层文件系统”处理。但别忘了,FUSE “守护进程”本身也是一个“应用程序”,所以千万注意不要让“守护进程”去访问自己负责的文件系统,否则就死循环了 ヾ(•ω•`)o 。
- 两次请求,两次通过 VFS 层,来回进行用户态和内核态的切换,就意味着这玩意儿的性能不会好 (呼应一下上面 SDCardFS 的简介)。
注释:
- (1) 此处不考虑 FUSE Passthrough 。
来形象的代入一下一次 FUSE 请求:
- 应用访问
/sdcard/aaa。 - 请求在内核态兜了一圈被转发给了 FUSE “守护进程”。
- “守护进程” 根据请求访问
/data/media/<用户号>/aaa。 - “守护进程”把拿到的结果丢回内核态再兜一圈。
- 结果被交付给应用程序。
接下来,稍微再深入一点的了解这个过程吧,虽然也深不到哪里去。
从初始化开始
这一块内容主要聚焦于 FUSE 是如何被挂载并和“守护进程”取得联系的。这个过程牵扯到了不少系统模块,我会尝试以尽量简化的过程表述出来。
在这里,我们暂且忽略多用户,只关心主用户的情况。多用户会在后面再进行进一步分析。
一切的起点来自于 vold 的启动。 vold 即 volume daemon ,是位于 Android 框架和内核之间负责存储器相关事件传递和管理的底层服务。
vold 在启动时,会采用 hardcode 的方式创建“模拟存储卷”:
system/vold/VolumeManager.cpp
int VolumeManager::start() {
......
auto vol = std::shared_ptr<android::vold::VolumeBase>(
new android::vold::EmulatedVolume("/data/media", 0));
vol->setMountUserId(0);
vol->create();
......
}而这一“创建事件”,会被向上传递到框架中,转交给 StorageManagerService :
frameworks/base/services/core/java/com/android/server/StorageManagerService.java
@Override
public void onVolumeCreated(String volId, int type, String diskId, String partGuid,
int userId) {
synchronized (mLock) {
final DiskInfo disk = mDisks.get(diskId);
final VolumeInfo vol = new VolumeInfo(volId, type, disk, partGuid);
vol.mountUserId = userId;
mVolumes.put(volId, vol);
onVolumeCreatedLocked(vol);
}
}StorageManagerService 在经过一些处理后,会重新调用 vold 来挂载这个“模拟存储卷”:
(这里传入的参数包含一个回调,在下面绕完一圈这个回调会被执行到,可以先留个心眼)
frameworks/base/services/core/java/com/android/server/StorageManagerService.java
private void mount(VolumeInfo vol) {
......
mVold.mount(vol.id, vol.mountFlags, vol.mountUserId, new IVoldMountCallback.Stub() {
......
}于是我们又回到了 vold 中,关键点来了,卷的挂载操作会调用到 MountUserFuse() 函数,而基于 FUSE 的“模拟存储”文件系统正是在这里被挂载的:
status_t MountUserFuse(userid_t user_id, const std::string& absolute_lower_path,
const std::string& relative_upper_path, android::base::unique_fd* fuse_fd) {
std::string pre_fuse_path(StringPrintf("/mnt/user/%d", user_id));
std::string fuse_path(
StringPrintf("%s/%s", pre_fuse_path.c_str(), relative_upper_path.c_str()));
......
// Open fuse fd.
fuse_fd->reset(open("/dev/fuse", O_RDWR | O_CLOEXEC));
if (fuse_fd->get() == -1) {
PLOG(ERROR) << "Failed to open /dev/fuse";
return -1;
}
// Note: leaving out default_permissions since we don't want kernel to do lower filesystem
// permission checks before routing to FUSE daemon.
const auto opts = StringPrintf(
"fd=%i,"
"rootmode=40000,"
"allow_other,"
"user_id=0,group_id=0,",
fuse_fd->get());
result = TEMP_FAILURE_RETRY(mount("/dev/fuse", fuse_path.c_str(), "fuse",
MS_NOSUID | MS_NODEV | MS_NOEXEC | MS_NOATIME | MS_LAZYTIME,
opts.c_str()));
......
}我来翻译一下这个过程:首先,vold 对 /dev/fuse 设备被执行了一次 open() 操作,拿到了一个 fd (文件描述符)。接着,/dev/fuse 设备被挂载到了 /mnt/user/<用户号>/emulated ,挂载时这个 fd 会被作为参数传入。
注意到了吗?这个 fd 被存储在一个以指针形式传入的 unique_fd 中,接下来这个 fd 会被向上层层移交,在进程之间穿梭,最终被交到 FUSE “守护进程”的手中。
于是,FUSE “守护进程”的手里拿着这个 fd ,FUSE 被挂载时的参数里也装着这个 fd ,“守护进程”就这么和 FUSE 挂载点对应上了。
fd 在这里的作用就仿佛一个 token (1),是关联 FUSE 挂载点和“守护进程”的关键纽带。
- (1) 由于跨越了进程,fd 本身的数字值极有可能是不相同的,因此真正起到 token 效果的是这个 fd 在内核中对应的
struct file。这里涉及到 Binder 跨进程传递 fd 的过程,不再继续展开了。
嗯,那就接着看看这个 fd 是如何被层层移交直到到达“守护进程”的吧。
fd 被从 vold 传递回框架层的 StorageManagerService 发生在上面的 FUSE 挂载函数被执行完之后,通过一个回调的方式进行:
system/vold/model/EmulatedVolume.cpp
status_t EmulatedVolume::doMount() {
......
res = MountUserFuse(user_id, getInternalPath(), label, &fd);
......
callback->onVolumeChecking(std::move(fd), getPath(), getInternalPath(), &is_ready);
......
}于是我们又回到了这里,只不过上次走的是 mVold.mount() 路线,这次轮到执行里面的回调了:
private void mount(VolumeInfo vol) {
......
mVold.mount(vol.id, vol.mountFlags, vol.mountUserId, new IVoldMountCallback.Stub() {
@Override
public boolean onVolumeChecking(FileDescriptor fd, String path,
String internalPath) {
......
ParcelFileDescriptor pfd = new ParcelFileDescriptor(fd);
try {
mStorageSessionController.onVolumeMount(pfd, vol);
......
}
});
......
}可以看到,通过一次 IPC ,fd 被从 vold 里传了过来,接下来被转交给了 StorageSessionController 。StorageSessionController 则进一步创建并持有 StorageUserConnection ,并通过调用其 startSession() 方法将 fd 塞了进去:
frameworks/base/services/core/java/com/android/server/storage/StorageSessionController.java
public void onVolumeMount(ParcelFileDescriptor deviceFd, VolumeInfo vol)
throws ExternalStorageServiceException {
......
StorageUserConnection connection = null;
......
Slog.i(TAG, "Creating connection for user: " + userId);
connection = new StorageUserConnection(mContext, userId, this);
......
......
connection.startSession(sessionId, deviceFd, vol.getPath().getPath(),
vol.getInternalPath().getPath());
......
}然后,fd 被继续转交给了 StorageUserConnection 中的一个内部类 ActiveConnection:
frameworks/base/services/core/java/com/android/server/storage/StorageUserConnection.java
public void startSession(String sessionId, ParcelFileDescriptor pfd, String upperPath,
String lowerPath) throws ExternalStorageServiceException {
......
mActiveConnection.startSession(session, pfd);
}接下来又是一个关键点了:
frameworks/base/services/core/java/com/android/server/storage/StorageUserConnection.java
ActiveConnection 内部类
public void startSession(Session session, ParcelFileDescriptor fd)
throws ExternalStorageServiceException {
......
waitForAsyncVoid((service, callback) -> service.startSession(session.sessionId,
FLAG_SESSION_TYPE_FUSE | FLAG_SESSION_ATTRIBUTE_INDEXABLE,
fd, session.upperPath, session.lowerPath, callback));
......
}可以看出,我们给 waitForAsyncVoid 塞进了一个 lambda 表达式,很显然是一个回调,会在未来某时某刻再被执行。我压根就不关心它什么时候被执行,我只关心 service 是个啥?搞清楚 service 是什么非常重要,它可是 fd 将被交付给的对象。
那就接着深入看看:
frameworks/base/services/core/java/com/android/server/storage/StorageUserConnection.java
ActiveConnection 内部类
private void waitForAsyncVoid(AsyncStorageServiceCall asyncCall) throws Exception {
......
waitForAsync(asyncCall, callback, opFuture, mOutstandingOps,
DEFAULT_REMOTE_TIMEOUT_SECONDS);
}
private <T> T waitForAsync(AsyncStorageServiceCall asyncCall, RemoteCallback callback,
CompletableFuture<T> opFuture, ArrayList<CompletableFuture<T>> outstandingOps,
long timeoutSeconds) throws Exception {
CompletableFuture<IExternalStorageService> serviceFuture = connectIfNeeded();
......
return serviceFuture.thenCompose(service -> {
try {
asyncCall.run(service, callback);
} catch (RemoteException e) {
opFuture.completeExceptionally(e);
}
return opFuture;
}).get(timeoutSeconds, TimeUnit.SECONDS);
......
}看到这个 CompletableFuture 就已经明白了大半。
这个过程说白了是这样的:先去尝试连接到某个 ExternalStorageService ,在连接完成后通过 Binder 跨进程的调用其 startSession() 方法,同时把 fd 作为参数塞进去。由于“尝试连接”需要时间且不一定成功,因此这里构造了一个 waitForAsyncVoid() 框架来实现非阻塞的异步调用,看着很乱但目的还是很明确的。
所以,这里在寻找的某个 ExternalStorageService 是谁呢?
是 MediaProvider 里的 ExternalStorageServiceImpl !
于是,第二次进程间通信完成了。第一次通信时 fd 被从 vold 传到了 system server 中,第二次通信则是将 fd 继续传递到了 MediaProvider 的一个服务里。
有一点看起来已经很清晰了,那便是:FUSE 的“守护进程”,或者说 FUSE 在用户侧的实现,是由 MediaProvider 模块负责的。
继续向下吧,终于,该轮到“守护进程”启动了!
fd 被进一步的塞给了 FuseDaemon:
packages/providers/MediaProvider/src/com/android/providers/media/fuse/ExternalStorageServiceImpl.java
@Override
public void onStartSession(@NonNull String sessionId, /* @SessionFlag */ int flag,
@NonNull ParcelFileDescriptor deviceFd, @NonNull File upperFileSystemPath,
@NonNull File lowerFileSystemPath) {
......
FuseDaemon daemon = new FuseDaemon(mediaProvider, this, deviceFd, sessionId,
upperFileSystemPath.getPath());
daemon.start();
......
}需要注意的是,FuseDaemon 是一个线程,在这个线程上会执行 native 代码,并且直到 FUSE 崩溃才会返回永远不会返回。
这,正是“守护进程”的本体:
packages/providers/MediaProvider/src/com/android/providers/media/fuse/FuseDaemon.java
public final class FuseDaemon extends Thread {
......
/** Starts a FUSE session. Does not return until the lower filesystem is unmounted. */
@Override
public void run() {
......
native_start(ptr, mFuseDeviceFd, mPath); // Blocks
......
}
......
}进到 native 层看看:
packages/providers/MediaProvider/jni/FuseDaemon.cpp
void FuseDaemon::Start(android::base::unique_fd fd, const std::string& path) {
......
struct fuse_session
* se = fuse_session_new(&args, &ops, sizeof(ops), &fuse_default);
......
se->fd = fd.release(); // libfuse owns the FD now
......
......
LOG(INFO) << "Starting fuse...";
fuse_session_loop_mt(se, &config);
......
}可以看到,fd 最终被交给了 fuse_session_loop_mt() ,它是一个直到 FUSE 崩溃才会返回永远不会返回的方法,可以看作是在死循环的获取和处理文件请求。这个方法由 libfuse 提供,它是一个负责与内核中的 FUSE 驱动通过 /dev/fuse 进行通信的库,在这里不会去翻阅其具体细节。
到这里,总算是理清了 FUSE “模拟存储”的初始化过程,说简单也简单:
vold 挂载 FUSE 文件系统,并将 token(fd) 传递到 system server 。system server 启动并连接到位于 MediaProvider 中的“守护进程服务”,并将 token 塞给它。于是位于用户侧的 FUSE “守护进程” 就可以与之前的挂载点相配对,接收来自内核侧的文件请求并开始正常工作了。
工作过程
上面,我们在 FuseDaemon fuse_session_loop_mt() 时传入了一个 struct fuse_session:
packages/providers/MediaProvider/jni/FuseDaemon.cpp
void FuseDaemon::Start(android::base::unique_fd fd, const std::string& path) {
......
struct fuse_session
* se = fuse_session_new(&args, &ops, sizeof(ops), &fuse_default);
......
}在创建这个 struct fuse_session 时,我们又传入了一个 struct fuse_lowlevel_ops 的指针:
packages/providers/MediaProvider/jni/FuseDaemon.cpp
static struct fuse_lowlevel_ops ops{
.init = pf_init, .destroy = pf_destroy, .lookup = pf_lookup, .forget = pf_forget,
.getattr = pf_getattr, .setattr = pf_setattr, .canonical_path = pf_canonical_path,
.mknod = pf_mknod, .mkdir = pf_mkdir, .unlink = pf_unlink, .rmdir = pf_rmdir,
/*.symlink = pf_symlink,*/
.rename = pf_rename,
/*.link = pf_link,*/
.open = pf_open, .read = pf_read,
/*.write = pf_write,*/
/*.flush = pf_flush,*/
.release = pf_release, .fsync = pf_fsync, .opendir = pf_opendir, .readdir = pf_readdir,
.releasedir = pf_releasedir, .fsyncdir = pf_fsyncdir, .statfs = pf_statfs,
/*.setxattr = pf_setxattr,
.getxattr = pf_getxattr,
.listxattr = pf_listxattr,
.removexattr = pf_removexattr,*/
.access = pf_access, .create = pf_create,
/*.getlk = pf_getlk,
.setlk = pf_setlk,
.bmap = pf_bmap,
.ioctl = pf_ioctl,
.poll = pf_poll,*/
.write_buf = pf_write_buf,
/*.retrieve_reply = pf_retrieve_reply,*/
.forget_multi = pf_forget_multi,
/*.flock = pf_flock,*/
.fallocate = pf_fallocate,
.readdirplus = pf_readdirplus,
/*.copy_file_range = pf_copy_file_range,*/
};正是这个结构体,指定了哪些方法将被用来接收内核侧 FUSE 驱动发来的文件事件。
把这些方法全看一遍并没有什么意义,道理都是一样的,那我们就挑点上面的需求,看看在 FUSE “守护进程”中是如何实现的吧。
那就挑和目录结构相关的吧,在没有存储权限的情况下,应用也可以访问“模拟存储”,但是只能列出目录结构,看不到也不能访问一般目录下的一般文件 + 在没有存储权限的情况下,应用只能看到和访问自己在“媒体目录”下创建的媒体文件。
那么,先找到“列出目录结构”这一操作是被哪个方法所接收的:
packages/providers/MediaProvider/jni/FuseDaemon.cpp
static void pf_readdirplus(fuse_req_t req,
fuse_ino_t ino,
size_t size,
off_t off,
struct fuse_file_info* fi) {
ATRACE_CALL();
do_readdir_common(req, ino, size, off, fi, true);
}看名字就觉得是你了,接着往下看:
packages/providers/MediaProvider/jni/FuseDaemon.cpp
static void do_readdir_common(fuse_req_t req,
fuse_ino_t ino,
size_t size,
off_t off,
struct fuse_file_info* fi,
bool plus) {
......
node* node = fuse->FromInode(ino);
......
const string path = node->BuildPath();
......
h->de = fuse->mp->GetDirectoryEntries(req->ctx.uid, path, h->d);
......
......
if (do_lookup(req, ino, de->d_name.c_str(), &e, &error_code, FuseOp::readdir)) {
entry_size = fuse_add_direntry_plus(req, buf + used, len - used, de->d_name.c_str(),
&e, h->next_off);
......
fuse_reply_buf(req, buf, used);
}这个方法还是挺长的,但是仔细分析一下,还是能够分成不同的逻辑部分的(删去了一些我认为非主干的逻辑):
- 从 fuse inode 还原出路径。
- 获取目录信息。
- 根据目录信息建立 fuse dentry。
- 将结果返回给内核。
很显然,想要实现我们上面的“需求”,主要关注的是“获取目录信息”部分,也就是 fuse->mp->GetDirectoryEntries(req->ctx.uid, path, h->d) ,那就看看吧。
诶,等等,那个 mp 是个什么?
看定义,是个 MediaProviderWrapper ?嗯?MediaProvider 的包装器?是的,它是用来对 java 层的 MediaProvider 进行调用的。 Java 层在创建 native 层的 FuseDaemon 时就塞进了一个对 java 层 MediaProvider 的引用,至于有什么用,接着往下看:
packages/providers/MediaProvider/jni/MediaProviderWrapper.cpp
std::vector<std::shared_ptr<DirectoryEntry>> MediaProviderWrapper::GetDirectoryEntries(
uid_t uid, const string& path, DIR* dirp) {
// Default value in case JNI thread was being terminated
std::vector<std::shared_ptr<DirectoryEntry>> res;
if (shouldBypassMediaProvider(uid)) {
addDirectoryEntriesFromLowerFs(dirp, /* filter */ nullptr, &res);
return res;
}
JNIEnv* env = MaybeAttachCurrentThread();
res = getFilesInDirectoryInternal(env, media_provider_object_, mid_get_files_in_dir_, uid, path);
const int res_size = res.size();
if (res_size && res[0]->d_name[0] == '/') {
// Path is unknown to MediaProvider, get files and directories from lower file system.
res.resize(0);
addDirectoryEntriesFromLowerFs(dirp, /* filter */ nullptr, &res);
} else if (res_size == 0 || !res[0]->d_name.empty()) {
// add directory names from lower file system.
addDirectoryEntriesFromLowerFs(dirp, /* filter */ &isDirectory, &res);
}
return res;
}我们先不看这个方法的功能,在搞清它其中的 getFilesInDirectoryInternal() 究竟干了些什么之前,是看不清它的功能的。
先看 getFilesInDirectoryInternal() :
packages/providers/MediaProvider/jni/MediaProviderWrapper.cpp
std::vector<std::shared_ptr<DirectoryEntry>> getFilesInDirectoryInternal(
JNIEnv* env, jobject media_provider_object, jmethodID mid_get_files_in_dir, uid_t uid,
const string& path) {
......
ScopedLocalRef<jobjectArray> files_list(
env, static_cast<jobjectArray>(env->CallObjectMethod(
media_provider_object, mid_get_files_in_dir, j_path.get(), uid)));
......
}这个方法也超长,但实际上关键的操作只有一句,或者说,是这一句中的一部分:它向 java 层发起了调用,拿到了 java 层所返回的目录内容列表。
剩下的,只不过是在进行 java 层与 native 层之间类型的拼接转换而已。
去 java 层看看:
packages/providers/MediaProvider/src/com/android/providers/media/MediaProvider.java
public String[] getFilesInDirectoryForFuse(String path, int uid) {
final LocalCallingIdentity token =
clearLocalCallingIdentity(getCachedCallingIdentityForFuse(uid));
PulledMetrics.logFileAccessViaFuse(getCallingUidOrSelf(), path);
try {
if (isPrivatePackagePathNotAccessibleByCaller(path)) {
return new String[] {""};
}
if (shouldBypassFuseRestrictions(/*forWrite*/ false, path)) {
return new String[] {"/"};
}
// Do not allow apps to list Android/data or Android/obb dirs.
// On primary volumes, apps that get special access to these directories get it via
// mount views of lowerfs. On secondary volumes, such apps would return early from
// shouldBypassFuseRestrictions above.
if (isDataOrObbPath(path)) {
return new String[] {""};
}
// Legacy apps that made is this far don't have the right storage permission and hence
// are not allowed to access anything other than their external app directory
if (isCallingPackageRequestingLegacy()) {
return new String[] {""};
}
// Get relative path for the contents of given directory.
String relativePath = extractRelativePathWithDisplayName(path);
if (relativePath == null) {
// Path is /storage/emulated/, if relativePath is null, MediaProvider doesn't
// have any details about the given directory. Use lower file system to obtain
// files and directories in the given directory.
return new String[] {"/"};
}
// For all other paths, get file names from media provider database.
// Return media and non-media files visible to the calling package.
ArrayList<String> fileNamesList = new ArrayList<>();
// Only FileColumns.DATA contains actual name of the file.
String[] projection = {MediaColumns.DATA};
Bundle queryArgs = new Bundle();
queryArgs.putString(QUERY_ARG_SQL_SELECTION, MediaColumns.RELATIVE_PATH +
" =? and mime_type not like 'null'");
queryArgs.putStringArray(QUERY_ARG_SQL_SELECTION_ARGS, new String[] {relativePath});
// Get database entries for files from MediaProvider database with
// MediaColumns.RELATIVE_PATH as the given path.
try (final Cursor cursor = query(FileUtils.getContentUriForPath(path), projection,
queryArgs, null)) {
while(cursor.moveToNext()) {
fileNamesList.add(extractDisplayName(cursor.getString(0)));
}
}
return fileNamesList.toArray(new String[fileNamesList.size()]);
} finally {
restoreLocalCallingIdentity(token);
}
}好,现在我们有足够的信息量来结合上面被暂时跳过的 GetDirectoryEntries() 了,这整个过程应该是这样的:
在尝试列出目录内容时:
- 对于启用了“分区存储”的应用(也就是代码中的一般情况),java 层从
MediaProvider数据库中获取在该路径下应用能够看见的“媒体文件”列表并返回,native 层则在这个基础上补上目录项,于是最终返回的内容就满足了我们上面的“需求”。 - 对于那些不能访问的目录,或者应用的 target api 较低没有启用分区存储且没有读取权限,java 层返回一个
{""},此时 native 层啥也不会补充,于是最终返回了一个空的文件列表。 - 对于拥有全权访问权限的目录(比如
Android/data中的包名目录),或者拥有MANAGE_EXTERNAL_STORAGE权限的应用,又或者 target api 较低没有启用分区存储但是拥有读取权限的应用,java 层会返回一个{"/"},此时 native 层会补充所有的文件项和目录项,于是最终返回的结果就是完整的目录内容。
当然,这里说的几种情况并不能完整覆盖所有的 case ,因此具体还得看上面的代码了 (●'◡'●) 。
于是到这里,我们也算是明白了 FuseDaemon 持有对 java 层 MediaProvider 引用的作用——它要访问 MediaProvider 数据库!(于是,IO 性能被进一步降低了)
诶,有没有发现什么问题?我们在调用比如说 shouldBypassFuseRestrictions() 之类的“鉴权”函数时并没有传入 uid ,那这些函数是怎么知道该鉴谁的权?
同理,在没有存储权限时,按照需求,返回的只能是“该应用”创建的媒体文件列表,可是在 query() 的时候我们压根没告诉它自己是谁,那它是怎么匹配的?
答案就藏在一开始就执行的 clearLocalCallingIdentity() 里。
MediaProvider 将请求者的身份信息存储在一个 ThreadLocal 变量 mCallingIdentity 里,在需要鉴权的地方会直接对这个变量进行调用。而第一行的 clearLocalCallingIdentity() 将请求者的身份替换为了发起请求的应用(1) ,于是接下来的操作就拿着对应应用的“身份证”了(和 Binder 挺像),比如说上面提及的判断媒体文件是否由该应用创建:
packages/providers/MediaProvider/src/com/android/providers/media/MediaProvider.java
private boolean checkCallingPermissionGlobal(Uri uri, boolean forWrite) {
......
final int table = matchUri(uri, true);
switch (table) {
case AUDIO_MEDIA_ID:
case VIDEO_MEDIA_ID:
case IMAGES_MEDIA_ID:
case FILES_ID:
case DOWNLOADS_ID:
final long id = ContentUris.parseId(uri);
if (mCallingIdentity.get().isOwned(id)) {
return true;
}
break;
default:
// continue below
}
......
}就是一个对 mCallingIdentity 的直接调用。
- (1) 由于发起请求的对象是 FUSE “守护进程”它自己,因此这里需要对 calling identity 进行替换。但假如这是一个普通的来自 Binder 的 ContentProvider 调用,就不再需要这种手动替换了,calling identity 会自动的被设置好。
于是到此为止,也算是对 FUSE “守护进程”的工作方式有了一个初步的了解了吧。它下接内核层,上探 java 层,不但实现着 SDCardFS 难以实现的复杂鉴权,还与 MediaProvider 数据库相同步与配合,也算是一个相当强大与复杂的设计了。
多用户
FUSE 的多用户要比 SDCardFS 来的复杂,因为 SDCardFS 不管有多少用户都只会被挂载一次,而 FUSE 却由于其守护进程是 per-user 的,因此不得不被挂载多次才能与“守护进程”一一对应。
在非主用户启动时,其用户对应的“模拟存储”卷会被创建:
system/vold/VolumeManager.cpp
void VolumeManager::createEmulatedVolumesForUser(userid_t userId) {
// Create unstacked EmulatedVolumes for the user
auto vol = std::shared_ptr<android::vold::VolumeBase>(
new android::vold::EmulatedVolume("/data/media", userId));
vol->setMountUserId(userId);
mInternalEmulatedVolumes.push_back(vol);
vol->create();
......
}然后和先前的流程一样,事件被传递到 StorageManagerService ,接着 StorageManagerService 操作 vold 对“模拟存储”进行挂载。
挂载的流程也和之前几乎完全一样,同样是将 /dev/fuse 挂载到了 /mnt/user/<用户号>/emulated ,和之前唯一的区别是这里的“用户号”不再是 0 (主用户号)。
然后还是和之前一样,fd 被传递,只不过这次传递的终点变成了对应用户中的 MediaProvider 中的“守护进程”。
于是,现在,一个用户中的“守护进程”负责一个 /mnt/user/<用户号>/emulated 挂载点,无论是存储的内容还是 MediaProvider 数据库都相互独立,非常的符合多用户要求。
不过需要注意的是,FUSE 挂载点的“根视图”同样是 /data/media 目录的视图,而并非其中的某个“用户文件夹”,这与 SDCardFS 是相同的。
所以,想要在 FUSE 的 /mnt/user 挂载点处访问不同用户下的文件,应该访问这样的目录:/mnt/user/<用户号>/emulated/<用户号> 。
不过,在默认情况下, FUSE “守护进程”会屏蔽对非当前用户文件夹的 lookup() ,因此 ls /mnt/user/<用户号>/emulated 时是看不到其它用户的文件夹的(1) 。
- (1) 前提是系统没有工作在 FUSE + SDCardFS 的叠加态,这一叠加态会导致对
emulated文件夹的 lookup 出现权限问题,下面再解释。
问题来了,可以看到 FUSE 一开始被分用户的挂载到了 /mnt/user 下,可是应用对“模拟存储”的访问往往用的是 /storage/emulated 啊?这两者又是如何联系起来的呢?
答案是,对于在不同用户中运行的应用,Zygote 启动应用时会在应用的独立命名空间中 bind mount 对应的 FUSE 挂载点:
frameworks/base/core/jni/com_android_internal_os_Zygote.cpp
static void MountEmulatedStorage(uid_t uid, jint mount_mode,
bool force_mount_namespace,
fail_fn_t fail_fn) {
......
// Create a second private mount namespace for our process
ensureInAppMountNamespace(fail_fn);
......
const userid_t user_id = multiuser_get_user_id(uid);
const std::string user_source = StringPrintf("/mnt/user/%d", user_id);
......
BindMount(user_source, "/storage", fail_fn);
......
}即 /mnt/user/<用户号> 会被 bind mount 到 /storage 。
所以
- 对于用户 0 中的一般应用,其访问
/storage/emulated/0等效访问/mnt/user/0/emulated/0,其访问/storage/emulated/10等效访问/mnt/user/0/emulated/10(虽然这个访问会被拒绝)。 - 对于用户 10 中的一般应用,其访问
/storage/emulated/10等效访问/mnt/user/10/emulated/10,其访问/storage/emulated/0等效访问/mnt/user/10/emulated/0(虽然这个访问会被拒绝)。
于是,应用就这么和 FUSE 挂载点对应了起来。
杂谈
访问身份
最终对“下层文件系统”的文件操作是由 MediaProvider 中的“守护进程”发起的,而这个“守护进程”并非运行在 uid=0 下,因此也会受到各种各样的权限限制(假如有的话)。
“守护进程”除了持有上面所说的 EVERYBODY 组号外,还持有一个高权限的 MEDIA_RW 组号。在一般情况下,这些组号能够确保其在 /data/media 下自由穿梭畅行无阻。但,假如你手动创建一个 MediaProvider 没有权限访问的文件夹,那自然通过其 FUSE 挂载点的访问也只能得到一个 permission denied 。
访问路径
如果你有仔细研究过 FUSE “守护进程”的代码,你会发现一些很有意思的点:
static void pf_getattr(fuse_req_t req,
fuse_ino_t ino,
struct fuse_file_info* fi) {
......
node* node = fuse->FromInode(ino);
......
const string& path = get_path(node);
......
struct stat s;
memset(&s, 0, sizeof(s));
if (lstat(path.c_str(), &s) < 0) {
fuse_reply_err(req, errno);
} else {
fuse_reply_attr(req, &s, std::numeric_limits<double>::max());
}
}就以这里的向内核转发来自下层文件系统的 stat 为例,你可以打印一下 path ,照理说它应该是“下层文件系统”的路径吧?但是,打印出来的结果却会发现它是以 /storage/emulated 开头的。这是怎么回事?在 FUSE 里访问 FUSE 文件系统?这不就死循环了么?
别慌,还记得我们上面提到的通过 bind mount 在 FUSE 挂载点与 /storage/emulated 之间建立联系吗?这种联系是对于一般应用而言的。
而 MediaProvider 显然非常的特殊:
frameworks/base/services/core/java/com/android/server/StorageManagerService.java
private int getMountModeInternal(int uid, String packageName) {
......
if (mStorageManagerInternal.isExternalStorageService(uid)) {
// Determine if caller requires pass_through mount; note that we do this for
// all processes that share a UID with MediaProvider; but this is fine, since
// those processes anyway share the same rights as MediaProvider.
return StorageManager.MOUNT_MODE_EXTERNAL_PASS_THROUGH;
}
......
}它的“挂载模式”被指定为了 pass through ,而这个 pass through 的对象显然就是 FUSE 。也就是说,MediaProvider 本身会被标记为“绕过 FUSE”。
那,在 MediaProvider 的“挂载命名空间”中,/storage/emulated 会是谁的 bind mount 呢?
回到上面出现过的,Zygote 在启动应用时会调用的 MountEmulatedStorage() 方法:
frameworks/base/core/jni/com_android_internal_os_Zygote.cpp
static void MountEmulatedStorage(uid_t uid, jint mount_mode,
bool force_mount_namespace,
fail_fn_t fail_fn) {
......
if (mount_mode == MOUNT_EXTERNAL_PASS_THROUGH) {
const std::string pass_through_source = StringPrintf("/mnt/pass_through/%d", user_id);
PrepareDir(pass_through_source, 0710, AID_ROOT, AID_MEDIA_RW, fail_fn);
BindMount(pass_through_source, "/storage", fail_fn);
} ......
} else {
BindMount(user_source, "/storage", fail_fn);
}
}可以看到,被标记为 pass through 的应用,在其“挂载命名空间中”,/storage 并不是 /mnt/user/<用户号> 的 bind mount ,而是 /mnt/pass_through/<用户号> 的 bind mount 。
那 /mnt/pass_through/<用户号> 又是个啥呢?
在一般情况下,它是“下层文件系统”的直接 bind mount:
system/vold/Utils.cpp
status_t MountUserFuse(userid_t user_id, const std::string& absolute_lower_path,
const std::string& relative_upper_path, android::base::unique_fd* fuse_fd) {
......
std::string pre_pass_through_path(StringPrintf("/mnt/pass_through/%d", user_id));
std::string pass_through_path(
StringPrintf("%s/%s", pre_pass_through_path.c_str(), relative_upper_path.c_str()));
......
return BindMount(absolute_lower_path, pass_through_path);
......
}也就是说,一般情况下,MediaProvider 访问 /storage/emulated 等于直接访问 /data/media 。
至于为什么 /mnt/pass_through 要通过用户号弄成 per-user 的,我也不知道,我觉得这是毫无意义的,所有用户共享一个就足以。
调试方法
有没有什么办法,能够在 shell 环境下伪装成普通应用,去体验一番只有一般应用才能体验到的“分区存储”呢?
答案是有的,只需要切换 uid + “挂载命名空间”即可,然后你就会被 FUSE “守护进程”当成普通应用来对待了。
参见“铺垫”一节中提及的文章。
小结
也算是大概的了解了一下 FUSE 的工作过程以及其与 Android 系统配合的相关操作,分析的并没有很深入,也没有牵扯到太多底层的内容。就这样吧,不想看了,主要是兴趣已经燃尽了。
不过,看完这些东西,你觉得还能像网上说的那样,通过一行 prop 关掉 FUSE 切回 SDCardFS 吗?
FUSE over SDCardFS
接下来,介绍一种神奇的 FUSE + SDCardFS 叠加态,在上面应该提到过了一嘴。
不知道你有没有注意到,在某些搭载 Android 11 以上系统的设备上,某些检测软件仍然会将内部存储的文件系统显示为 SDCardFS :
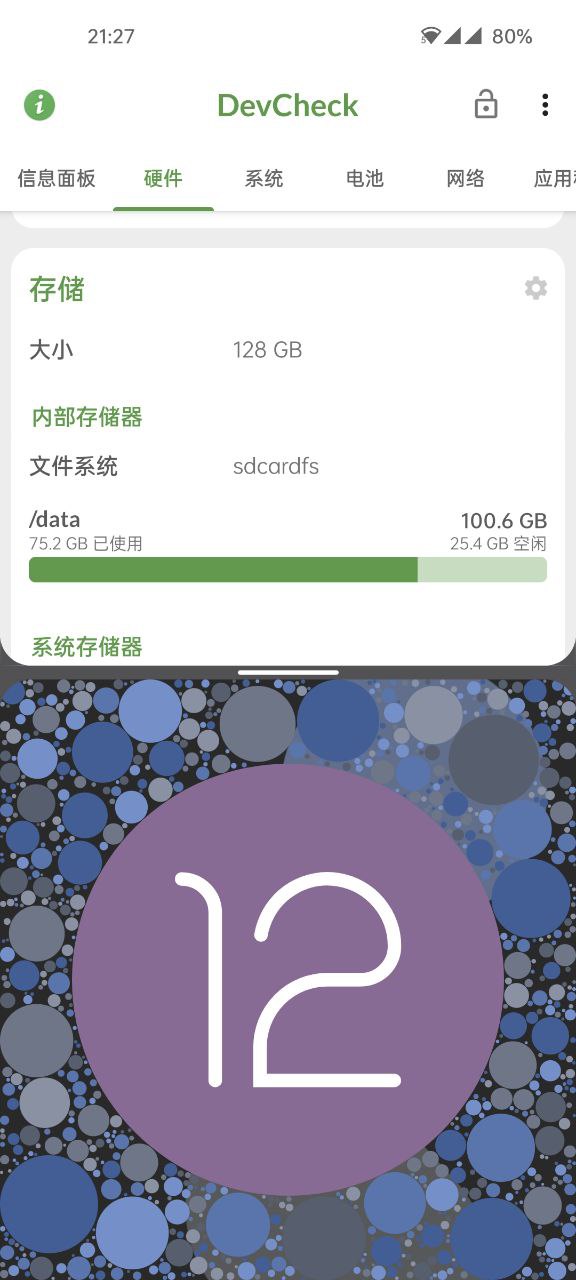
是它搞错了吗?不,这不是空穴来风,这是事实:“模拟存储”的文件系统既是 FUSE 又是 SDCardFS 。
诶?难道不是 SDCardFS 被丢弃,换上了 FUSE ?这俩不应该是相互替代的关系么?
谁告诉你的?仔细想想,这俩东西压根就没有工作在同一层面——假如 MediaProvider 所访问的“下层文件系统”是个 SDCardFS ,那会怎样?
而这正是这种叠加态的工作方式。
上面在介绍 /mnt/pass_through 时所提到的 MountUserFuse() 函数,其实被我省略掉了一些东西,现在将部分省略的东西复原:
system/vold/Utils.cpp
status_t MountUserFuse(userid_t user_id, const std::string& absolute_lower_path,
const std::string& relative_upper_path, android::base::unique_fd* fuse_fd) {
......
std::string pre_pass_through_path(StringPrintf("/mnt/pass_through/%d", user_id));
std::string pass_through_path(
StringPrintf("%s/%s", pre_pass_through_path.c_str(), relative_upper_path.c_str()));
......
if (IsSdcardfsUsed()) {
std::string sdcardfs_path(
StringPrintf("/mnt/runtime/full/%s", relative_upper_path.c_str()));
LOG(INFO) << "Bind mounting " << sdcardfs_path << " to " << pass_through_path;
return BindMount(sdcardfs_path, pass_through_path);
} else {
LOG(INFO) << "Bind mounting " << absolute_lower_path << " to " << pass_through_path;
return BindMount(absolute_lower_path, pass_through_path);
}
}可以看到,在 IsSdcardfsUsed() 的条件下,/mnt/pass_through/<用户号> 不再是 /data/media 的 bind mount ,而是变成了 /mnt/runtime/full/emulated 的 bind mount ,此时的“下层文件系统”不再直接是 /data/media ,而正是如上面所说的那样,变成了 SDCardFS !因此,在上面我强调过“在一般情况下”,这种情况就很不一般。
那么,IsSdcardfsUsed() 的触发条件是什么?
简单来说,只要内核没有移除 SDCardFS 支持,那它就会默认触发,自动选择 SDCardFS 作为 FUSE 的“下层文件系统”。对于 5.4 以上内核,SDCardFS 已经被移除了,永远也不会跑到这条路径里来。对于 5.4 以下内核的设备,你可以通过设置 prop external_storage.sdcardfs.enabled=false 来强制采用 /data/media 作为 FUSE 的“下层文件系统”,更正规的方式是在 device.mk 中 $(call inherit-product, $(SRC_TARGET_DIR)/product/emulated_storage.mk) ,这 emulated_storage.mk 中就包含了上述 prop 。
那么?为什么呢?
简单来说,还是兼容性问题:
- 之前也有看到过,SDCardFS 对于存储在“下层文件系统”上内容的权限有着特殊的处理,贸然 drop 掉 SDCardFS 有可能会导致 MediaProvider 失去对“下层文件系统”的访问权限,需要双清来恢复,这显然不太“兼容”吧?
- FUSE 本身并没有做“忽略大小写”的设计,这个功能被设计为依赖内核中的文件系统驱动来实现(详见
emulated_storage.mk中的其他内容)。而旧的内核显然并不太支持这个玩意儿,于是“模拟存储”就失去了不区分大小写的功能...这不太好吧。
接下来来回答上面留下的问题:
不过,在默认情况下, FUSE “守护进程”会屏蔽对非当前用户文件夹的 `lookup()` ,因此 `ls /mnt/user/<用户号>/emulated` 时是看不到其它用户的文件夹的(1) 。
- (1) 前提是系统没有工作在 FUSE + SDCardFS 的叠加态,这一叠加态会导致对 `emulated` 文件夹的 lookup 出现权限问题,下面再解释。ls /storage/emulated 操作在采用 SDCardFS 作为“下层文件系统”时会直接 permission denied (即使采用 root 身份运行),怎么回事呢?
我想,这是因为在创建这些目录时,并没有给 MediaProvider 留足权限:
status_t EmulatedVolume::doMount() {
......
mSdcardFsDefault = StringPrintf("/mnt/runtime/default/%s", label.c_str());
mSdcardFsRead = StringPrintf("/mnt/runtime/read/%s", label.c_str());
mSdcardFsWrite = StringPrintf("/mnt/runtime/write/%s", label.c_str());
mSdcardFsFull = StringPrintf("/mnt/runtime/full/%s", label.c_str());
......
if (fs_prepare_dir(mSdcardFsDefault.c_str(), 0700, AID_ROOT, AID_ROOT) ||
fs_prepare_dir(mSdcardFsRead.c_str(), 0700, AID_ROOT, AID_ROOT) ||
fs_prepare_dir(mSdcardFsWrite.c_str(), 0700, AID_ROOT, AID_ROOT) ||
fs_prepare_dir(mSdcardFsFull.c_str(), 0700, AID_ROOT, AID_ROOT)) {
PLOG(ERROR) << getId() << " failed to create mount points";
return -errno;
}
}于是,在使用 SDCardFS 作为 FUSE 的下层文件系统时,它们被 bind mount 到 /mnt/pass_through/<用户号> ,把这权限也带了过来,于是由于 MediaProvider 的权限不足,“根视图”就无法被读取了。
总结
太长了都忘了自己写过什么了,那就不总结了吧,看番去了,溜了。
高质量博客👍👍已连翻多帖