前言
inotify 是一种常见的文件系统事件监听方法,Boost.Asio 是一个常见的 c++ 网络与异步 I/O 库。
它们有结合在一起使用的可能性吗?
有一个奇怪的需求:我想在一个本来使用了 asio 的应用中额外引入对 inotify 机制的使用,但 inotify 需要额外持续 read() 一个 fd ,这意味着需要额外启一个线程;额外启一个线程是不理想的,可能引入新的同步问题。所以有没有一种方法,能够将 inotify 的 fd 与 asio 的异步操作机制相结合,规避新线程的创建呢?
调查 asio
(↓ 这一部分牵扯到的代码全部 using namespace boost::asio ,为了方便就省略掉命名空间前缀了)
很奇怪的是,asio 作为网络库是知名的,但若只是使用其基本的异步 I/O 功能,在网上却很难找到相关资料。而且,asio 的官方文档实在是简陋到有点幽默了。
在犄角旮旯的地方找到了一份 ppt ,里面描述了使用 asio 进行基本文件 I/O 操作的方式:
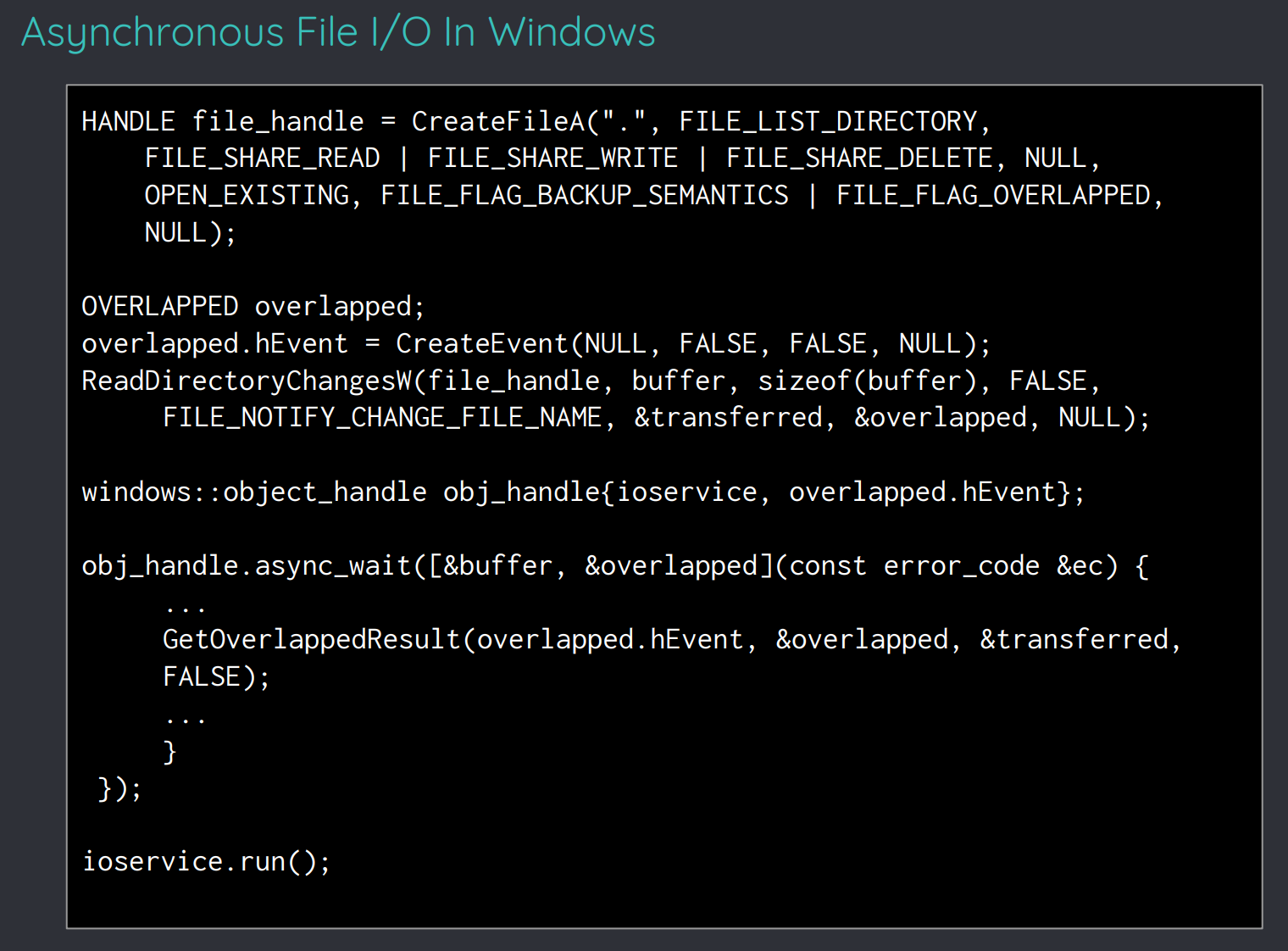
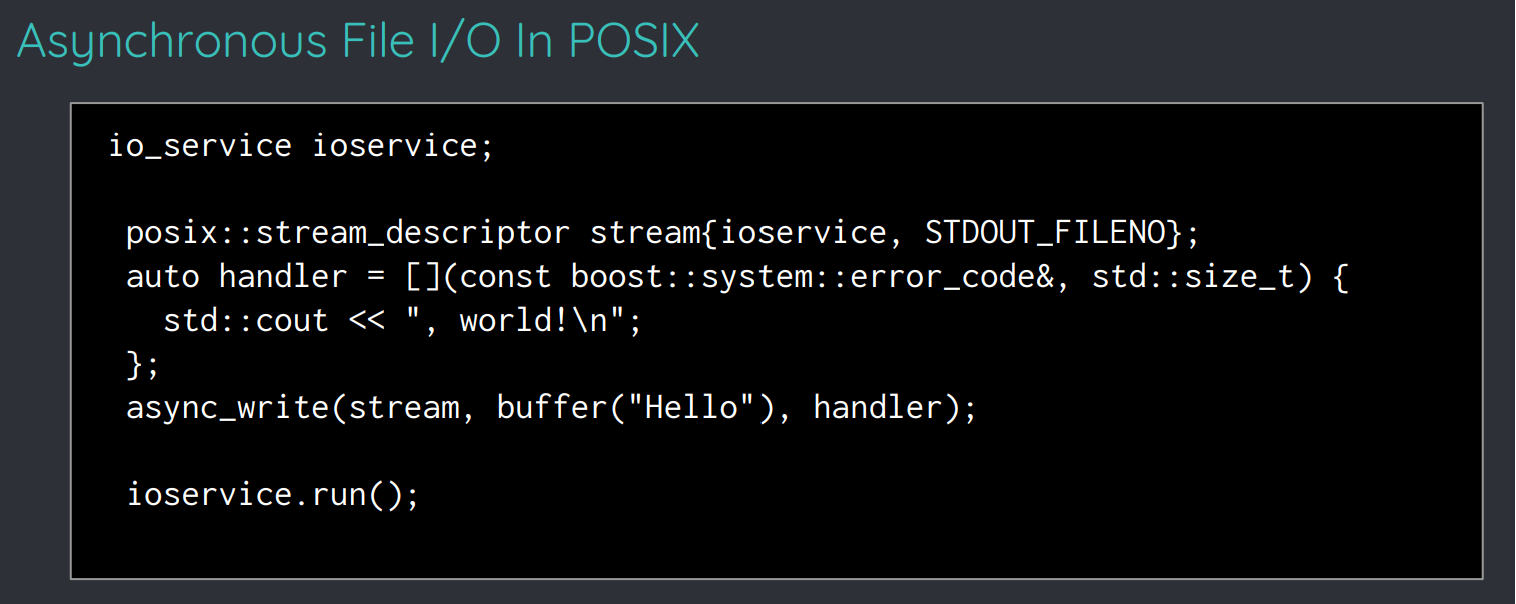
并且,其中还提到:

虽然 asio 提供了通用的网络操作 api ,但似乎没有提供通用的文件操作 api 。
也许,这种不通用性便是 asio 在异步文件操作上没有被广泛使用的原因吧。
其实我很好奇为什么网络 api 可以被通用化,而文件 api 却不行,在 unix 平台上它们都是类似的 fd ,在 windows 上难道它们差异很大吗?
就不深入研究这种平台差异了,先来聚焦于 POSIX 上 asio 的文件操作,来看看里面牵扯到的各个东西是如何作用的。
io_service ioservice;
posix::stream_descriptor stream{ioservice, STDOUT_FILENO};
auto handler = [](const boost::system::error_code&, std::size_t) {
std::cout << ", world!\n";
};
async_write(stream, buffer("Hello"), handler);
ioservice.run();(其实现在 asio 是支持跨平台的文件读写操作的,见下面的“通用文件操作 api”部分,不过这个东西可能是新版加入的,之前没有?)
io_context
io_service 在新版 asio 库中已被 io_context 取代,它是一个 I/O 事件的复用/解复用器。
在说到 I/O 复用时,我们先来设想下面这个场景:我有两个 fd ,分别是 A 和 B ,它们随时都可能有数据过来,因此我需要持续监听它们。正常的监听就是去 read() ,或者说,blocked read ,也就是在数据到来之前 read() 是不会返回的。既然我有两个文件描述符需要监听,那是不是意味着我要同时进行两个 read() ,那我岂不是要开两个线程?
为了优化这种情况,操作系统往往会提供一系列的 I/O 复用机制,说白了就是让一个线程能够监听多个文件描述符,那么它是怎么做到的呢?
以 linux 上的 epoll 为例:
1、首先,创建一个 epoll fd 。
2、将我们需要监听的 A 和 B 绑定到这个 epoll fd。
3、对这个 epoll fd 执行 epoll_wait()。
4、当 A 或 B 发生 I/O 事件时(比如可以读到东西了),epoll_wait() 便会返回,此时我们可以根据 epoll_event 得知发生事件的 fd 是哪个,然后再去处理对应事件(比如去实际 read() 它,把数据拿出来)。
如果上面的解释还不够清晰,可以再看看这篇文章。
梳理上面这个过程,会发现其实它由两部分组成:
1、复用:将需要监听的文件描述符 attach 到 epoll fd 上。
2、解复用:当事件发生时,弄清楚是哪个 fd 触发了事件,并采取对应的方式来处理事件。
于是我们就可以直观的理解 io_context :它是一个 epoll 的包装,负责处理 I/O 事件与回调之间的关系。比如你想异步读取文件描述符 A 和 B ,那么在 asio 内部,A 和 B 就都会被绑定到 io_context 内部的 epoll fd 上,并将请求交给内核处理;当 A 「或」 B 的数据准备好时,epoll_wait() 就会返回,此时 asio 需要根据事件信息,确认产生事件的 fd 是 A 还是 B ,并将事件分发给正确的回调。io_context 所做的事情,便是去维护 fd 与事件回调之间的关系,使得一批 I/O 事件能被“复用”到一个 epoll 上,epoll_wait() 返回时又能够被“解复用”到正确的回调函数上。当然,这里描述的 epoll 只是 linux 平台的特例,在不同平台上 io_context 有不同的实现,比如在 windows 上大概用得是 IOCP ?
当然,除了基本的 I/O 监听,io_context 还能实现如简单异步执行(io.post())和定时器(steady_timer)之类的高级操作(大概依靠 eventfd 和 timerfd 实现),所以宏观的来看,它完全可以扮演一个事件队列的角色(就像 Android 中的 Looper 一样),只不过是一个额外支持了网络和文件事件的高级事件队列。
有了上面的这些铺垫,最后一行的 ioservice.run() 就变得非常好理解,它就等价于 Looper.loop()) ,放在 asio 的语境下也就是开始在这个线程循环执行 epoll_wait() ,并在发生事件时执行对应的回调。所以,asio 确实可以利用 I/O 复用机制大大减少处理大量 I/O 事件所需的线程数,但最终一定要有一个线程负责处理所有的事件,这个线程便是执行 io.run() 的线程。在大多数 asio 程序的设计中,主线程会被用于事件处理,于是就可以看到 main() 函数的最后一行被写上了 io.run() / ioservice.run() ,正常情况下,这些 run() 都是永不返回的,事件监听和处理会一直持续进行。
wrappers
posix::stream_descriptor 和 buffer() 都是一层简单的包装,分别提供了对文件流和内存区域的抽象。这层抽象能够为 asio 的其它部分提供统一的接口,使其在一定程度上能够屏蔽平台差异并确保安全性,参见下方的“asio 中的 concept”。
async_write
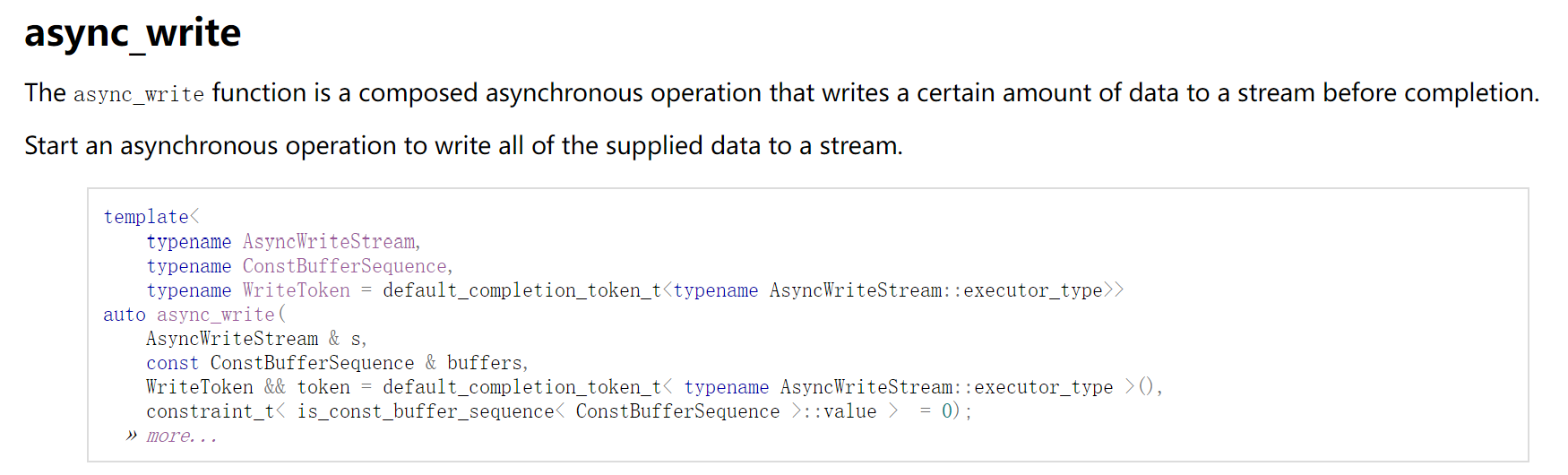
在这一块内容中,我想要首先聚焦于如何看懂 asio 的文档。
不觉得上面这图很怪吗?它给了 async_write 作为函数模板的定义,但是,入参的类型都是模板的类型参数,那我该怎么知道这个模板能够接受什么样的参数呢?
举个例子:
template<typename T>
T plus(T t1, T t2) {
return t1 + t2;
}我们一眼就能知道,对于上面这个模板,只有能相加的东西作为参数传入时才能通过编译,传一个未重载 operator+() 的对象进去多半是要报错的,但是,这种 T 的所需特性并没有体现在模板的签名中,比如 T extends Addable(伪 java )。对于上面图中的 AsyncWriteStream 和 ConstBufferSequence 也是如此,它们都只是模板的 typename ,并没有体现所需对象的特性,所以,就没有一种东西能够体现这种特性吗?
Concept
Basically ,对象的所需特性其实是一种抽象。在一般的编程语言中,这种抽象由类或接口的继承来实现。
但是 c++ 比较特殊,除了由类和虚函数实现的运行时多态外,它还有基于模板实现的编译时多态:模板基于传入的类型进行展开,然后执行编译,在编译成功/失败之前,模板本身并不能知道参数是否与模板中的语法匹配。就比如对于上面的 plus() ,模板本身并没有能力检查传入的类型是否支持 operator+() ,对所有的传入类型它都只能老老实实的展开和编译,只是没有实现 operator+() 的类型无法通过编译罢了。于是,这就提供了相当高的灵活性:任何执行 + 时不会编译出错的对象都能被填入到这个模板中,而无需关心这些对象继承了啥父类。这在别的语言如 java 中是难以实现的:毕竟 java 中可没有类似 Addable 这样的接口,想要实现这种 plus() 得为每个基本类型实现一个函数重载。
当然,除了特殊的 operator+() ,这种编译时多态也能被应用于一般的函数,比如:
struct A {
void bar() {};
};
struct B {
void bar() {};
};
struct C {
void bar1() {};
};
template<typename T>
void foo(T t) {
t.bar();
}
int main() {
// 调用 A 的 bar()
foo(A());
// 调用 B 的 bar()
foo(B());
// 编译出错,C 类型没有 bar()
foo(C());
return 0;
}任何拥有方法 bar() 的类型都可以被传入这个模板,然后顺利通过编译。与虚函数不同的是,t.bar() 具体调用哪个 bar() 是由模板展开时的类型推导决定的,而非由虚表决定,因此这种编译时多态相较运行时多态有着更好的性能;同时,这些类也不需要继承于某个基类,提供了相当高的灵活性。成功与否的唯一决定因素便是:模板展开后是否有语法错误,能否成功通过编译。
回到正题,既然这种基于模板的编译时多态也是一种抽象,那该如何表示对 T 的约束呢?比如 T 必须可相加,T 必须拥有 bar() 方法。难道必须等到模板展开后编译,依靠编译报错来判断它是否符合要求吗?我们就不能在模板展开之前拦截不符合要求的类型吗?
对此,c++ 20 引入了一套“概念”(Concept)处理机制,即将“能够相加”、“拥有 bar() 函数”等一个个通过编译的约束条件抽象成“概念”,并允许使用一系列的语法在模板展开前对“概念”进行拦截和处理。也就是说,对于 c++ 来说,运行时多态抽象出来的东西叫“基类”,而编译时多态抽象出来的东西叫“概念”。
当然,自从模板存在的那一天起,“概念”就一直存在,c++ 20 所引入的是一套优化后的概念处理机制,而非“概念”本身,比如让概念不匹配时打印出更加友好的报错,又或者为原来的 SIFNAE 提供封装,让模板匹配的逻辑变得易懂一些,这里有一篇关于 c++ 20 concept 的介绍,看起来还不错。
asio 中的 concept
对于 asio 来说,它(到目前为止)并没有使用 c++ 20 的概念处理机制。但是,这并不意味着 asio 没有对“概念”的抽象,事实上,只要点进这里的链接,就能看到其对这些类型的“概念”要求:
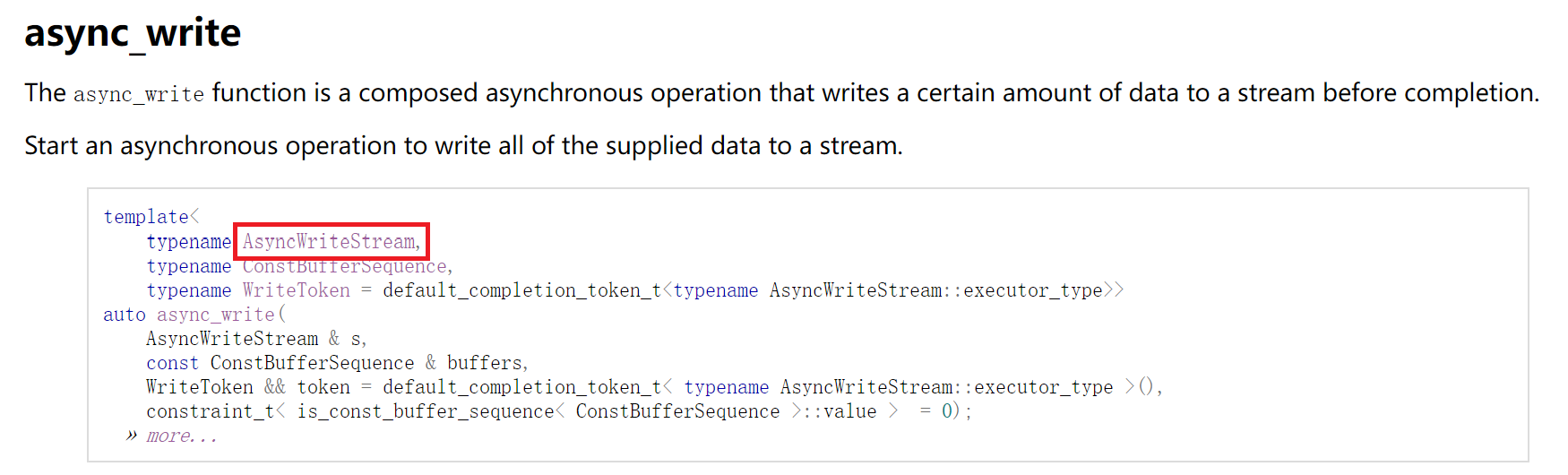

比如,async_write() 的第一个参数是一个 AsyncWriteStream 的概念,它必须拥有 get_executor() 和 async_write_some() 方法。任何一个拥有这俩方法的对象,理论上都能被 async_write() 接受并通过编译。
很难受的是,我们得自己去找什么东西符合 AsyncWriteStream 的概念,asio 好像并没有一个文档来说明哪些东西支持这一概念,但是,不管怎么样,posix::stream_descriptor 一定是符合这一概念的,为 windows 平台封装的 windows::stream_handle 也是符合这一概念的。
同理,async_write() 的第二个参数必须符合 ConstBufferSequence 的概念,这一概念要求该参数能通过 buffer_sequence_begin() 和 buffer_sequence_end() 转换为对应的迭代器。
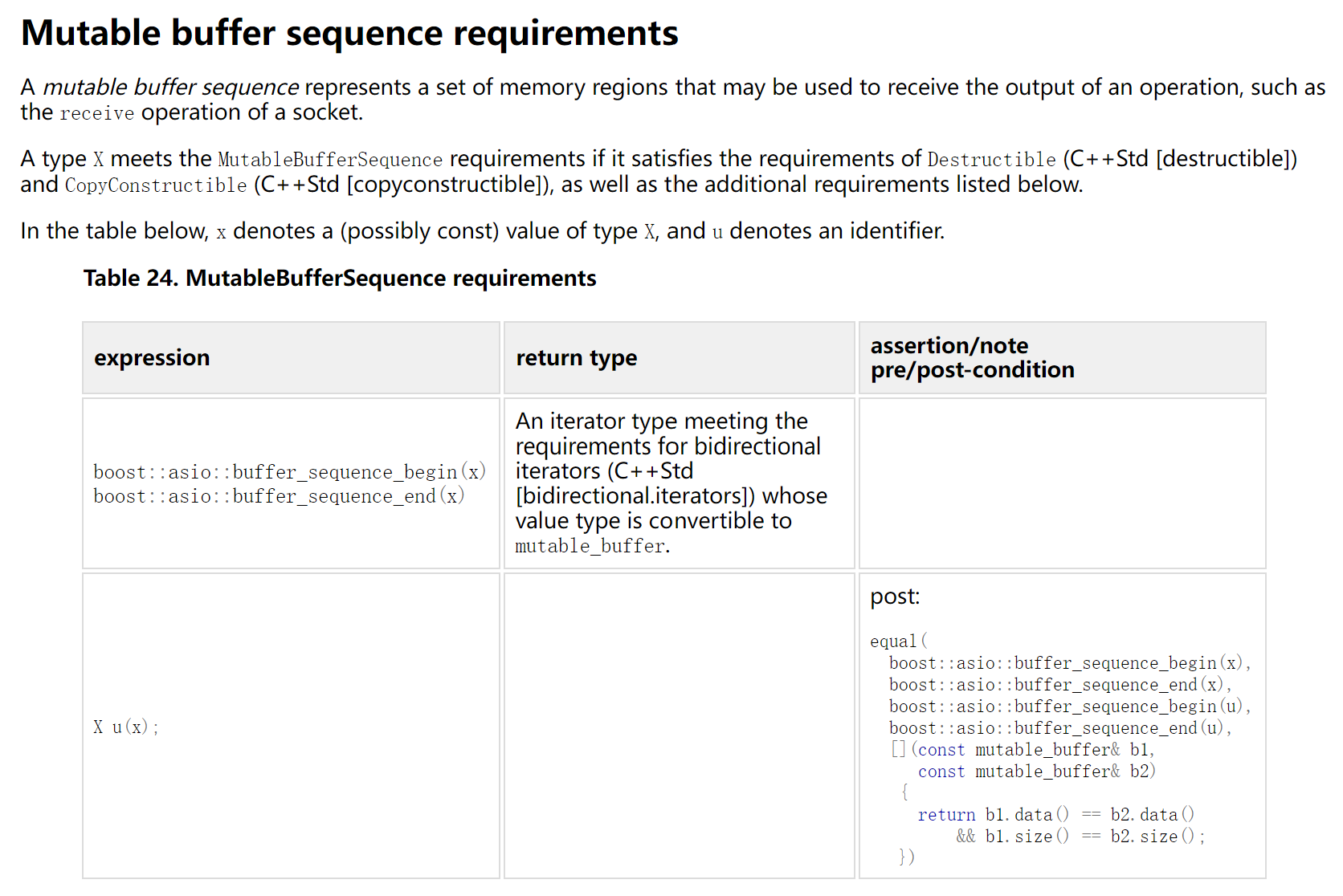
我们上面代码中的 buffer("Hello") 其实就是将 "Hello" 所在的常量地址包装成了一个 const_buffer ,这个 const_buffer 可以通过 buffer_sequence_begin() / buffer_sequence_end() 转换为迭代器,因此 buffer("Hello") 是符合 ConstBufferSequence 概念的,它可以通过编译。
async_write() 的最后一个参数也是同理,具有特定签名的 callable object 是符合 WriteToken 概念的,于是我们的 handler 可以被成功传入。
(这里先暂且忽略其它种类的 Completion Tokens,聚焦于 callable object )
对于 handler ,其函数签名的要求为 void(error_code, size_t) 。error_code 代表可能出现的意外情况,比如在写入失败时,handler 也会被调用,但此时 error_code 会有值,代表失败的原因;第二个 size_t 则普通的代表写入的字节数。
也许你会注意到,async_write() 在其模板定义中还有一个参数:
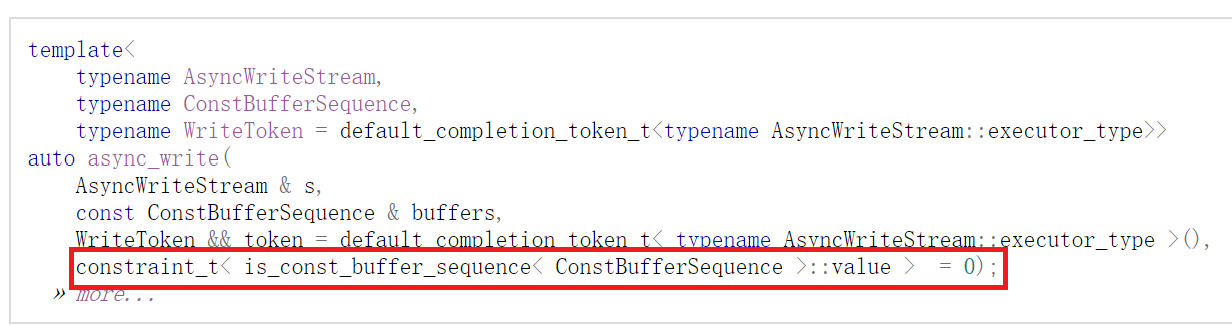
这个参数并不是给用户使用的,它只在编译期间被用于辅助模板的展开过程,是 SIFNAE 机制的应用:它对第二个模板参数进行了校验,当第二个参数的类型不符合 ConstBufferSequence 的概念与约束时,及时告诉编译器不要展开此模板,而是去选择其它的模板重载。
(嗯,c++ 20 引入的概念处理机制也是来解决此类问题的,不过 asio 使用的仍是传统的 SIFNAE 方案)
async_write 到底做了什么?
This operation is implemented in terms of zero or more calls to the stream's async_write_some function, and is known as a composed operation. The program must ensure that the stream performs no other write operations (such as async_write, the stream's async_write_some function, or any other composed operations that perform writes) until this operation completes.
可以看到,async_write() 所做的,便是去多次调用 AsyncWriteStream 概念的 async_write_some() 方法,直到 buffer 的内容被全部写入到了文件流中。无论是 async_write() 还是 async_write_some() ,都会在被调用后立刻返回,不会阻塞。你可能会注意到 async_write() 和 async_write_some() 在函数签名上没有本质区别,那是因为它们在本质上做着相同的事情,只是 async_write_some() 不会确保 buffer 的内容被全部写入到流中,而 async_write() 通过比较 buffer 大小和已写入大小,通过多次调用 async_write_some() 来实现了这一层保障。
(以下内容含有一定的猜测成分,我并没有研究过 boost 的代码 ↓ )
对于一次 async_write() ,所做的事情大概是这样的(假设传入的 handler 叫 handler ):
1、创建一个 handler1 ,调用 async_write_some() 。
2、在 handler1 中比较 buffer 大小和已写入大小,若未完全写入则再次执行 async_write_some() ,直到发生错误或完全写入(形成一个“递归”的异步操作链)。
3、如果发生错误,则将错误信息从 handler1 中转发到 handler 中,通知上层。
4、如果全部写入完成,则通过 handler 通知上层,并汇报写入的总字节数。
对于一次 async_write_some() ,所做的事情大概是这样的(假设传入的 handler 叫 handler1 ):
1、尝试以非阻塞模式(1)调用同步的 write() 将目标 buffer 写入目标 fd 中。
2、如果一次成功,则直接调用 handler1 ,全部结束。
3、如果没有成功,比如同步的 write() 返回了 -EAGAIN ,代表此时因为如缓冲区不足之类的原因无法写入。那么其会将目标 fd attach 到 io_context 上,监控目标 fd 的写就绪事件(EPOLLOUT),并在目标 fd 可写时再无阻塞的执行 write() ,并将写入的字节数通过 handler1 汇报给上层。
不过,我猜一般情况下是没这么复杂的,一般情况下 async_write_some() 在尝试 write() 时会直接成功,而且一次性写入了全部的内容,那就直接通过 handler 向上返回了,看似异步的写入其实做了个同步操作。只有在目标 fd 阻塞无法写入时,io_context 才会起到作用,避免阻塞以最大化效率,发挥 I/O 复用和异步操作的优势。
注释:
- (1) 对这个地方还是有点疑问,asio 会自动将 fd 设置为
O_NONBLOCK模式吗?还是说需要在传入 fd 前手动设置?我没有具体测过写入的情况,但在读取时,未手动设置O_NONBLOCK似乎对结果并没有影响,也不会阻塞io_context中的其它操作。我不确定这是因为 asio 会自动处理O_NONBLOCK,还是因为 asio 在读取前额外采用FIONREADioctl 进行了判断,使得问题没有暴露出来。但在写入时,可没有这样的额外 ioctl 可以辅助判断是否阻塞啊。所以,现在我并不确定如果未将 fd 设置为O_NONBLOCK模式,是否会导致异步写入变身同步写入,等待进一步确认。And stackoverflow 上也有一个关于异步变同步疑问的帖子,目前还没人回答,可以一起观察一下。
看看其它东西
上面我们的分析全部是围绕那个 ppt 中的示例代码展开的,基本只分析了 async_write() ,别忘了我们想做的是去读 inotify 事件,那不妨来看看读相关的函数吧。
我想要将 asio 中异步读取相关的函数分为几类:
1、async_read(stream, buffer, handler) / stream.async_read_some(buffer, handler)
异步的顺序读取文件流,区别是 async_read_some() 只读一次,能读到多少是多少,而 async_read() 则会在内部“异步递归”执行 async_read_some() ,直到装满 buffer 或出错为止。
它们与我们之前介绍的 async_write()、async_write_some() 是对称的。
posix::stream_descriptor 和 windows::stream_handle 支持该操作。
2、async_read_at(stream, offset, buffer, handler) / stream.async_read_some_at(offset, buffer, handler)
异步的随机读取文件流,相较于上面的顺序版本多了个 offset 可以用来指明从何开始读取。
它们与 async_write_at()、async_write_some_at() 是对称的(这些是异步随机写入方法,虽然之前没有介绍)。
很有趣的是,posix::stream_descriptor 并不支持这一操作,只有 windows::random_access_handle 支持此操作。
(当然,这并不意味着 linux 没法随机访问文件,见下面的“通用文件操作 api”)
3、async_read_until(stream, dynamic_buffer, delimiter, handler)
异步的顺序读取文件流,但不根据 buffer 大小停止,而是根据 delimiter 停止。delimiter 相当于停止标识符,是一个 char ,比如 \n 。
这里所需要的 buffer 与上面的不同,上面所需要的都是大小固定的 buffer ,而这里需要的是大小可变的 dynamic buffer (实现 DynamicBuffer_v1 概念)。dynamic buffer 可以利用 streambuf 创建,也可以使用类似 dynamic_buffer(string) 或 dynamic_buffer(vector) 的方式创建,总之得传入一个可以 resize() 的容器,数据也会被实际存储在这个容器中(因此得保障好它的生命周期)。
async_read_until() 在内部调用的也是 async_read_some() ,因此支持该操作的流对象与 read some 是相同的。
通用文件操作 api
还记得上面的 Currently, File I/O is not supported in a platform independent manner 吗?
诶,仔细看了一下官方 reference ,其实 asio 完全是支持跨平台的文件操作的(可能是新版本加入的?)。
上面,我们只提及了 posix::stream_descriptor(io, fd)、windows::stream_handle(io, handle)、windows::random_access_handle(io, handle) 等平台特有的流对象,但 asio 实际上还提供了更通用的跨平台文件流封装:
stream_file(io, path, flags)—— 支持顺序读写的跨平台文件流对象,支持上面的所有顺序读写函数(async_read()、async_read_some()、async_read_until()、async_write()、async_write_some())。random_access_file(io, path, flags)—— 支持随机读写的跨平台文件流对象,支持上面的随机读写函数(async_read_at()、async_read_some_at()、async_write_at()、async_write_some_at())。
诶,那这些通用 api 和 posix::stream_descriptor 有啥区别呢?为什么 posix::stream_descriptor 不能支持随机读写呢?
我想,这是因为 posix::stream_descriptor 是为“万物皆文件”而准备的,任何一个 fd 都可以被塞进去,无论它是文件、socket、设备还是管道,这里面只有文件是能够 seek() 的,其它的很多东西是只能顺序读写的。既然是去抽象一个可以代表万物的文件描述符,那自然而然随机读写就不在考虑范围内了。
而 stream_file 和 random_access_file 显然是简化了这一抽象,它们只能代表实际有路径的文件,拿它们和 posix::stream_descriptor 比较就好比拿 FILE *f = ... 和 int fd = ... 比较,前者有 stdio 的封装来确保跨平台兼容性,后者却是 unix 特有的,这里所蕴含的道理是一样的。
除了跨平台的文件流封装,asio 还提供了跨平台的管道封装:readable_pipe(io)、writable_pipe(io)
它们支持单向的读或写操作。
虽然这看起来很怪,但它确实是跨平台的,可以在这里找到官方介绍。
实现:结合 inotify
终于要回到正题了,接下来看看 inotify ,再看看怎么把它结合到 asio 中去。
inotify 的基本使用是简单的,可以在 man7 上找到详细文档,也可以在 stackoverflow 上找到最简用例。
总的来说,inotify 的最简使用分成三步:
1、int fd = inotify_init() 创建一个 inotify fd 。
2、inotify_add_watch(fd, "/path/to/target/directory", 目标事件) 增加要监听的目标事件。
3、read(fd, buf, buf_size) 读取事件,将事件存入 buf 中,读到的事件是 struct inotify_event。
struct inotify_event 的定义如下,它是一个特殊的变长结构体:
struct inotify_event {
int wd; /* Watch descriptor */
uint32_t mask; /* Mask describing event */
uint32_t cookie; /* Unique cookie associating related
events (for rename(2)) */
uint32_t len; /* Size of name field */
char name[]; /* Optional null-terminated name */
};其中,len 代表了 name 的实际大小(包括 name 末尾的 \0),因此一个 inotify_event 的实际大小为 sizeof(struct inotify_event) + event->len 。
对于事件的读取和处理,有一些注意点:
- 默认情况下
read()发生的是阻塞读取,会一直阻塞到有事件为止。 - 一次 read 可能读取到一个或多个变长的
struct inotify_event,处理时要特别小心。 - 选择 buf 大小时要注意,由于
struct inotify_event是变长的,buf 至少得能够装下一个满长的struct inotify_event,因此 buf 空间至少需要预留sizeof(struct inotify_event) + NAME_MAX + 1。 - 如果选择 buf 大小为
sizeof(struct inotify_event) + NAME_MAX + 1,也就是恰好装下一个满长事件,并不意味着一次只会读到一个事件,因为 buffer 仍然可以装下多个不满长的事件。因此,无论选择多大的 buffer 大小,都要考虑一次读到多个事件的可能性,不能一次read()只处理一个事件,而是要通过比较读到的总大小和单个事件的大小,确保所有事件都得到了正确的处理。
处理一次读到的多个事件,示例代码如下:
int sizeRead = read(fd, buf, sizeof(buf));
char* pos = buf;
// 直到本次读到的全部数据都被处理完为止
while (pos - buf < sizeRead)
{
// 取出单个事件
struct inotify_event* event =
reinterpret_cast<struct inotify_event*>(pos);
// 在此处理单个事件
// 跳过本事件,后面可能还有别的事件
pos += sizeof(struct inotify_event) + event->len;
}好,接下来该考虑一下如何整合进 asio 里了。
首先,该选择哪个读取方法?async_read()?async_read_some()?async_read_until()?
首先排除 async_read_until() ,因为事件之间是没有合适的分隔符的,其次排除 async_read(),因为事件是变长的,我压根没法决定读取多少内容才算结束。
所以唯一的选择是 async_read_some()。
那么又有下一个问题了,一次 async_read_some() 只代表“读一次,在有结果时调用回调”,那么我该如何实现持续监控呢?这里可不能像同步读取一样用 while(1) 啊。
诶,那么,我们就得在一次 async_read_some() 的回调中执行下一次 async_read_some() ,形成一种“异步递归”结构,当然,这种递归即使无限下去也是不会爆栈的,因为它是异步的,下一次回调时原来的栈早就析构了。
于是,最终实现的代码如下:
#include <fcntl.h>
#include <sys/inotify.h>
#include <boost/asio.hpp>
#include <functional>
#include <iostream>
#include <memory>
// 选择一个最小的缓冲区大小,恰好装下一个满事件。
static constexpr const size_t eventBufSize =
1 * (sizeof(struct inotify_event) + NAME_MAX + 1);
// 处理单个事件
static void onEventReceived(struct inotify_event* event)
{
std::string_view fileName(event->name);
std::cout << fileName << std::endl;
// 你的自定义操作
}
// async_read_some() 的原始 handler ,需要处理一次读到多个事件的情况,并安排“异步递归”
static void rawEventHandler(
std::shared_ptr<boost::asio::posix::stream_descriptor> stream, char* buf,
const boost::system::error_code& ec, size_t sizeRead)
{
if (ec)
{
std::cerr << "Failed when reading inotify event " << ec.message()
<< std::endl;
return;
}
// 缓冲区中可能存在多个事件,逐一对其进行处理
char* pos = buf;
while (pos - buf < sizeRead)
{
struct inotify_event* event =
reinterpret_cast<struct inotify_event*>(pos);
onEventReceived(event);
// inotify_event 是个可变长度结构体,必须加上 len 才能得到其实际长度
pos += sizeof(struct inotify_event) + event->len;
}
// 本次读取完成,准备下次读取
stream->async_read_some(boost::asio::buffer(buf, eventBufSize),
std::bind_front(rawEventHandler, stream, buf));
}
static void setupInotify(boost::asio::io_context& io)
{
// static 或在堆上分配,确保长期有效
// 是实际存储结果的地方
static char buf[eventBufSize];
// 需要确认这里到底要不要手动配置 nonblock ,见“async_write 到底做了什么?”的注释 1
// 实测读操作没有影响,那么写呢?
// 作为最佳实践,我觉得还是配一下比较安全
// int fd = inotify_init();
int fd = inotify_init1(IN_NONBLOCK);
if (fd < 0)
{
std::cerr << "Unable to set up inotify" << std::endl;
return;
}
// 不妨来监控这个事件
inotify_add_watch(fd, "/home/libxzr", IN_CREATE);
// stream 需要保持长期有效,因此不能在栈上分配,当然你也可以 static
auto stream = std::make_shared<boost::asio::posix::stream_descriptor>(io,
fd);
// 将 stream 的智能指针传递到 bind 形成的闭包之内,延续其生命周期
// async_read_some 需要固定大小的缓冲区,因此选择拿 buffer() 把上面的 buf 包一下
stream->async_read_some(boost::asio::buffer(buf, eventBufSize),
std::bind_front(rawEventHandler, stream, buf));
}
int main()
{
boost::asio::io_context io;
setupInotify(io);
// 理论上永不退出
io.run();
}编译与测试
sudo apt install libboost-system-dev
g++ -std=c++20 test.cpp
./a.out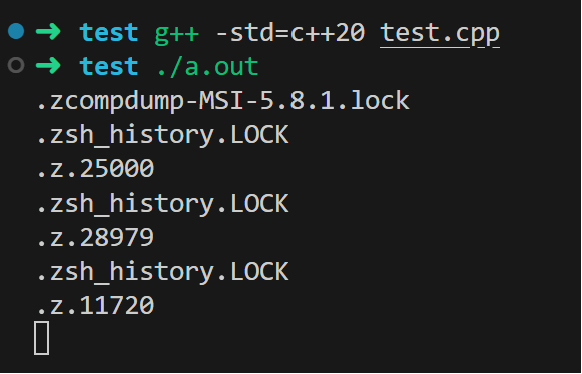
可以看到,已经成功监听到 inotify 事件了。
也许你会好奇为什么编译时不需要 -lboost_system ,那是因为 asio 是一个 header only 的库,只需要引用头文件就可以使用其全部功能。
参考资料
- https://www.boost.org/doc/libs/1_84_0/doc/html/boost_asio/reference.html
- https://stackoverflow.com/questions/3058310/boostasioasync-read-until-problem
- https://stackoverflow.com/questions/2790383/how-to-asynchronously-read-to-stdstring-using-boostasio
- https://corecppil.github.io/Meetups/2018-05-28_Practical-C++Asio-Variant/Asynchronous_IO_with_boost.asio.pdf
- https://segmentfault.com/a/1190000003063859
- https://learn.microsoft.com/en-us/windows/win32/fileio/i-o-completion-ports
- https://zhuanlan.zhihu.com/p/266086040
- https://en.cppreference.com/w/cpp/language/sfinae
- https://en.cppreference.com/w/cpp/language/constraints
这么好的文章,值得点赞!写的非常用心,非常好!