前言
前段时间有个概念很火,它被称为 FAS (Frame time Aware Scheduling) ,即根据帧生成时间而非处理器负载来调控处理器频率。这种操作能够在不影响帧率的前提下尽可能的降低处理器频率,从而改善游戏的能效。不少手机厂商也采取了类似的思路来改善游戏功耗,如小米的 FEAS 。
接下来,我想要明确一下接下来会用到的概念。首先是“帧时间”和“帧生成时间”,这两者看着类似但实际上是完全不同的。“帧时间”是两次显示内容改变之间的间隔,“帧生成时间”则是生成这一帧花费的时间。
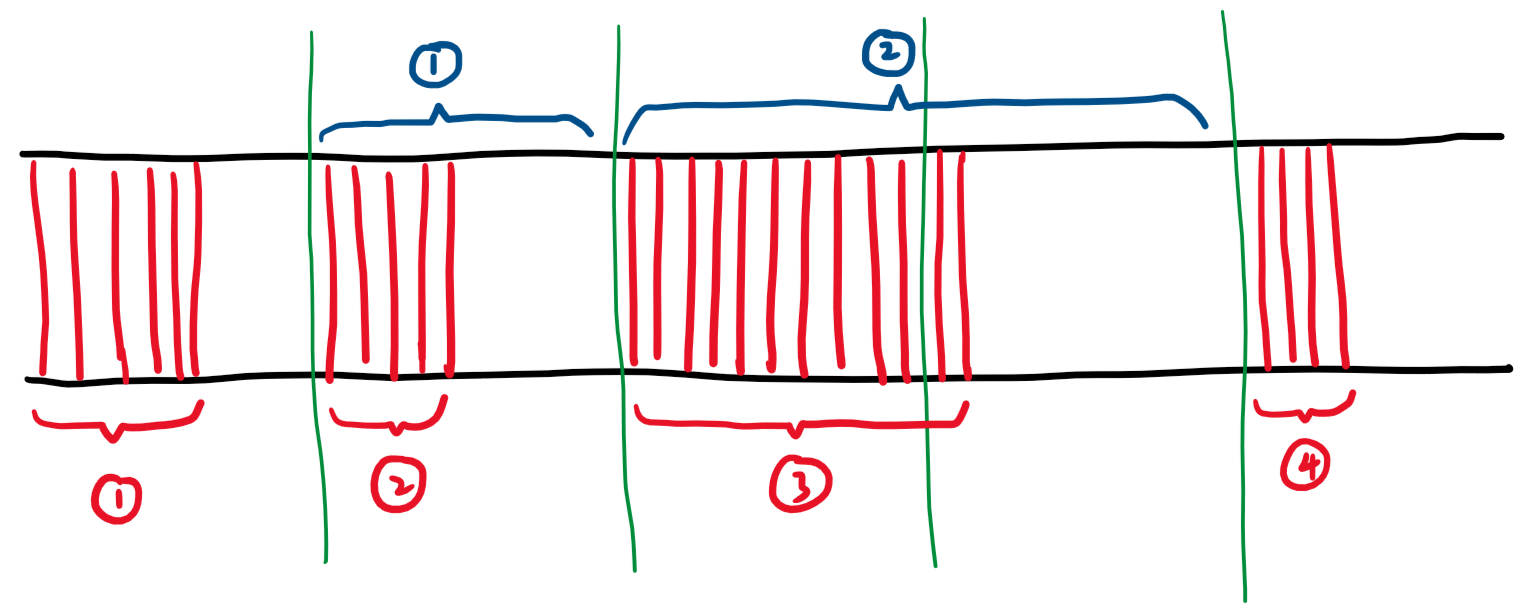
以上面手搓的这张图为例,这张图描述了简化的帧渲染——显示流程(1)。
上图中,横向为时间轴,绿色竖线代表在该时刻发生了 vsync 信号,红色部分代表新的帧正在生成。红色标号代表第 n 帧正在生成,蓝色标号代表第 n 帧正显示在屏幕上。
在 vsync 信号发生时,之前已经生成完毕的帧会被显示在屏幕上,而新一帧的生成也会开始。
我们来详细解释一下上面这张图:
- 首先,第 1 帧开始生成,这一帧的生成很快就完成了,但是必须等到 vsync 信号到来时才会被显示在屏幕上,于是它凭空等待了一会儿。
- vsync 信号到来,第 1 帧被显示在了屏幕上,此时第 2 帧的生成开始。第 2 帧的生成也很快就完成了,但必须继续等待下一个 vsync 信号。
- vsync 信号到来,第 2 帧被显示在了屏幕上,此时第 3 帧的生成开始。第 3 帧的生成看起来有点慢。
- vsync 信号到来,但是此时第 3 帧的生成还没有完成,于是屏幕显示的内容没有改变,第 2 帧继续显示在屏幕上。此时,我们便可以认为发生了丢帧。
- vsync 信号到来,这下第 3 帧已经生成好了,于是它被显示在了屏幕上,同时第 4 帧的生成开始了。
通过上面的这些解释,我想你应该能够更好的区分“帧时间”和“帧生成时间”了。在上面的图中,被蓝色括号包住的部分即为第 n 帧的“帧时间”,被红色括号包住的部分即为第 n 帧的“帧生成时间”。
可以看到,“帧生成时间”能够直接反应当前性能,假如某一帧的“帧生成时间”超过了 vsync 间隔(即屏幕刷新间隔),丢帧势必发生。
在丢帧已经开始发生时,“帧时间”也在一定程度上能够反应性能。
对于上面所说的 FAS ,最佳的实践方式是:使“帧生成时间”尽量从左侧逼近(小于等于)“屏幕刷新间隔”。但是,实际上,这并不是一件容易做到的事情,原因在于“帧生成时间”的数据实在是有些难以获取。一般而言,想要获取“帧生成时间”,是要对应用进程下手的,毕竟帧的渲染流程主要发生在对应的应用进程中(2)。“帧时间”则可以直接从 surfaceflinger 中获取,相对来说就会方便许多。
于是,现在常见的 FAS 实现,如 Scene FAS ,采用的都是使用“帧时间”来替代“帧生成时间”的方案,比如控制处理器频率使得“帧时间”尽量稳定。对于游戏类应用,这种方式其实就已经能够起到不错的效果了,因为游戏画面的帧率往往是稳定且连续的,但是对于日常应用,这可是要翻车的。日常应用中,我们可能会遇到许多画面完全静止的情况,比如在阅读时。在这种情况下,是不存在帧的刷新的(3),那么此时的“帧时间”将会变得非常大,但是,这能够说明此时因为性能不足而丢帧吗?并不能,因为此时是压根没有新的帧,而不是因为性能不足而丢帧。“帧时间”存在的这种缺陷使得 FAS 思想迟迟难以被使用到日常应用中。
这篇文章所展示的内容将会帮助解决这一困境,但也只能解决基于 libhwui 的普通 Android 应用的“帧生成时间”获取问题,对于采用自己渲染引擎的游戏类应用,到目前为止,使用“帧时间”代替“帧生成时间”仍然是最好的妥协方案。
注释:
- (1) 没错,这真的简化了很多东西,但拿来帮助理解我觉得完全没有问题。在真实情况下,由于 GPU 的异步性,还存在三重缓冲的问题,而且 vsync-sf 和 vsync-app 信号发生的时间也不一定是同步的,这些信号的发生时间甚至可能不是固定的,详见 (3) 。
- (2) 我曾经想过在 surfaceflinger 中把分发 vsync 信号到应用
queuebuffer()之间的间隔作为“帧生成时间”,但是没有成功,因为这对于在内核中操作来说太不友好了,需要大量的逆向和面向寄存器编程工作。但是,对于第三方 ROM ,这也许是一个可行的思路。不过鉴于应用在收到 vsync 后不一定会更新帧,那就还得弄清楚这个queuebuffer()属于哪一次 vsync 信号,还是有些难度👀。 - (3) surfaceflinger 自身使用的(vsync-sf)和向应用程序分发的(vsync-app) vsync 信号并不直接来自于 hwcomposer 。surfaceflinger 自身维护了一个软件 vsync 发生器,hwcomposer 发来的硬件 vsync 信号会被送去校准这一“软件发生器”。不必要时,硬件 vsync 信号甚至会被直接关闭掉。这也就意味着,软件发生的 vsync 信号不一定是规律且连续的,vsync-sf 和 vsync-app 信号之间也可以存在相位差。以 vsync-sf 信号为例,我的理解是这样的(不一定准确):只有在应用提交了 Graphic Buffer 后,surfaceflinger 才会 schedule 下一个 vsync-sf 来刷新屏幕;假如压根就没有应用提交 Graphic Buffer ,就不存在下一个 vsync-sf 信号,屏幕也就不会刷新。
从 uprobe 开始
Linux 内核提供了一种机制,通过替换应用内存页面中指定地址上的指令为“断点异常指令”,从而使应用在指定的时机陷入内核态并执行回调代码,这一机制被称为 uprobe 。
总的来说,这个过程是这样的:
- 替换指定地址上的指令为“断点异常指令”。
- 应用执行到该指令,陷入内核态。
- 在内核态查询注册的 uprobes 及其 handler ,并执行指定的回调。
- 单步执行之前被替换的指令。
- 恢复应用程序,使其在断点指令之后继续正常执行。
在陷入内核态时,刚刚应用处于用户态时的寄存器信息会被保存起来。在 uprobe 回调函数中,我们可以访问这些信息,甚至可以修改这些信息。
uprobe 的典型使用方法是基于 tracefs 的,就比如 官方使用指南 。但很遗憾,这种东西对于内核侧开发并没有什么帮助。在内核侧使用 uprobe api 相关东西的资料在网上也比较少,那接下来就简单介绍一下,投喂一下 new bing 。
以下内容基于 4.19 内核。
#include <linux/fs.h>
#include <linux/uprobes.h>
#define BINARY_PATH "/bin/my_binary"
#define OFFSET 0x114514
static int my_handler(
struct uprobe_consumer *self, struct pt_regs *regs)
{
pr_info("Here we are in uprobe callback");
return 0;
}
static struct uprobe_consumer my_consumer = {
.handler = &my_handler
};
static void my_uprobe_init(void)
{
struct path p;
struct inode *i;
int ret;
ret = kern_path(BINARY_PATH, 0, &p);
if (ret)
goto error;
i = d_inode(p.dentry);
ret = uprobe_register(i, OFFSET, &my_consumer);
if (ret)
goto clean;
return;
clean:
path_put(&p);
error:
pr_err("Unable to register uprobe, ret = %d", ret);
}可以看到,注册 uprobe 的关键函数是 uprobe_register(struct inode *inode, loff_t offset, struct uprobe_consumer *uc) 。这个函数需要传入三个参数,首先是那个需要被替换指令的文件的 inode ,其次是需要被替换的指令在文件中的偏移量,最后则是用以指定处理方式的 uprobe_consumer 。
inode 我们可以使用上面代码中所示的方式简单的拿到;偏移量则非常的关键,我们留到下面专门说;uprobe_consumer 中其实除了用来指定回调的 handler 外,还有用于指定 uretprobe 回调的 ret_handler ,以及用于过滤的 filter 。这些内容由于这里用不到就不再展开了,有兴趣可以自己去阅读相关代码。
接下来讲一讲非常关键的偏移量,这个点我感觉官方文档并没有讲清楚。这里的偏移指的是需要被替换的指令在文件中的偏移量,既不是该指令在虚拟地址空间中的地址,也不是该指令相对于 .text 段的偏移量。不知道为什么,官方文档 把在 .text 段中的偏移量当成在文件中的偏移量了。
接下来用一个小例子来看看这个偏移量该如何计算。
#include <stdio.h>
void hello()
{
printf("Hello\n");
}
int main(int argc, char *argv[])
{
int i = 10;
while (i--) {
hello();
}
return 0;
}这是一段非常简单的代码,它会调用 hello() 十次。
编译完成后(1),我们可以使用 readelf -s 命令打印 hello 函数在虚拟地址空间中的地址:
$ readelf -s obj/local/arm64-v8a/up-test | grep hello
46: 0000000000001744 28 FUNC GLOBAL DEFAULT 14 hello可以看到,其地址为 0x1744 。
接下来,我们使用 readelf -S 寻找 hello 所在的 .text 段在虚拟内存空间中的地址:
$ readelf -S obj/local/arm64-v8a/up-test | grep .text
[14] .text PROGBITS 00000000000016ac 000006ac在这里,0x16ac 即为 .text 段在虚拟内存空间中的地址。那么,0x6ac 又是什么呢?它是 .text 段在该文件中的偏移量。
此时,我们想要创建一个监控 hello 调用情况的 uprobe ,我们不妨就把断点放在 hello 的入口处吧,我们需要计算 hello 的入口处指令在文件中的偏移量。
我们已经掌握的是:hello 函数的虚拟地址、hello 所在的 .text 段的虚拟地址、.text 段在文件中的偏移量。
那这就是一个小学数学题了。
hello 的文件中偏移 = hello 的虚拟地址 - .text 段的虚拟地址 + .text 段在文件中的偏移
0x1744 - 0x16ac + 0x6ac = 0x7440x744 就是那个我们该用来注册 uprobe 的文件中偏移量。
当然,更简单的方法也不是没有,像 ida 之类的逆向软件,就会直接把文件内偏移量显示在底下:
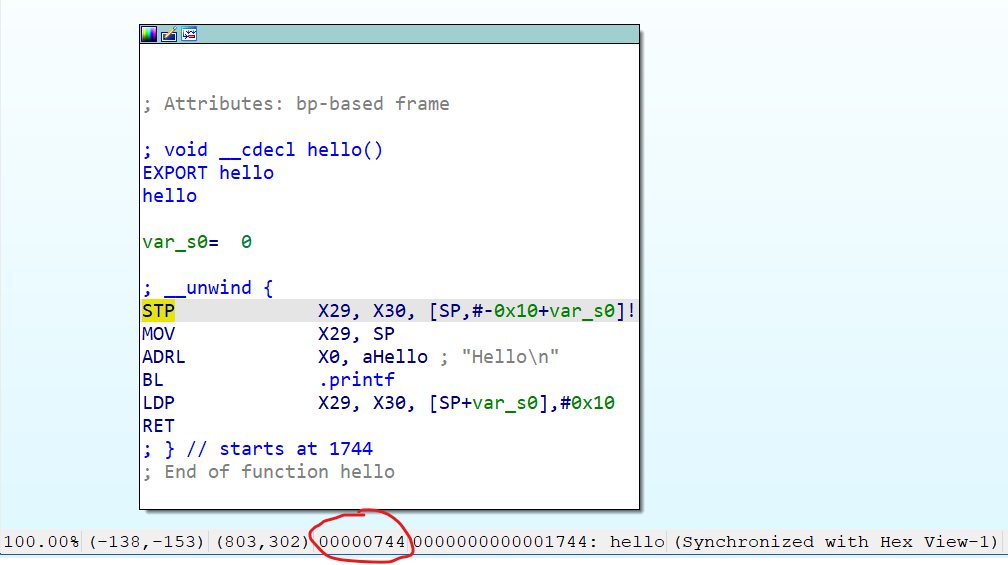
噢对了,回调函数还有个返回值,如果不想进行什么骚操作(比如触发了这个 uprobe 就移除它之类的),返回 0 即可。
注释:
- (1) 对于这种代码,编译器很容易把这个函数 inline 优化掉,所以记得加上 -O0 。此外,如果编译采用的是 Android NDK ,那么它会自动 strip 掉符号表,导致
readelf -s一片空白。解决方案是使用obj/下生成的中间产物,而非libs/下的最终产物。
帧生成时间数据源
这是一个相当头疼的点,上面我有写到 surfaceflinger 也许可以作为一个入手点,但是要从中区分出不同应用、区分出哪次 queuebuffer() 对应哪个 vsync 的难度极大。而且更关键的是编译完的 surfaceflinger 不会携带调试符号表,再加上它是 c++ 写的,逆向起来简直就是依托答辩:即使这次定位到了目标方法,下一次、换一个人、换台设备可能就只能以失败告终。
我突然想起了以前有个玄学叫做 “GPU 呈现模式分析” :
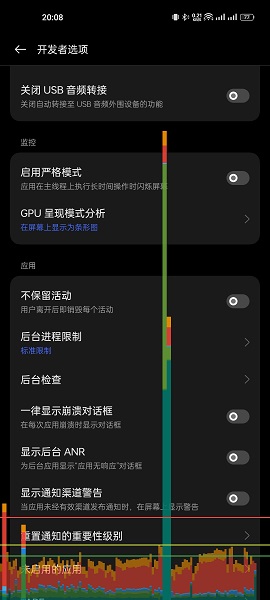
这玩意儿的数据源是什么?图表又是由谁画出来的?如果数据源在系统服务,那它是怎么搜集数据的?如果数据源在应用本身,那它是怎么把这些数据发给系统服务来画图的?
简单看了看代码,我发现我一个都没猜对,真实的情况是:应用自己搜集数据,应用自己画图。
也就是说,这个图并不是系统叠加上去了什么东西,而是应用在绘制完界面后又主动绘制了这幅图,从搜集数据到画图的过程中不存在任何的 IPC 。
那,为什么我一个开关就能控制一堆应用开始自己画图,这不是很奇怪吗?
在这背后,“GPU 呈现模式分析”的开关控制的是 debug.hwui.profile 这个 prop ,当这个 prop 的值为 visual_bars 时,各个应用就会开始主动画图了。
那,为什么应用们会千篇一律的监听这个 prop ,会自主搜集数据,还会画样式统一的图表呢?难道应用开发者们都提前约好了吗?
并没有约好,只是因为一般的 Android 应用都是基于平台 api 所提供的组件(比如 View )开发,而这些组件的硬件加速渲染过程会调用到系统自带的 libhwui 库,我们所熟知的 skiavk、skiagl 就是 libhwui 中渲染管线的一部分。事实上,上面监听 prop 和画图的过程本身就被做在 libhwui 当中,而数据搜集的过程是由预埋在平台 api 中的“时间采样点”完成的。所以简单回答上面的问题:虽然大家的应用会一起主动的搜集数据和画图,但这不是因为大家都写了搜集数据和画图的代码,而是因为大家使用的平台 api 本身就包含了这些东西。
并不是所有的应用都有这种默契,比如浏览器类和游戏类应用,它们往往有自己的渲染引擎,不会使用 libhwui 所提供的渲染管线。对于这些应用,我们就没法使用这种方法来获取“帧生成时间”了。
至此,我们明确了一般的应用其实都会默默搜集渲染相关性能数据的事实,这些数据原本是为 “GPU 呈现模式分析” 服务的,但是,现在轮到它们来服务我们了。
数据的搜集过程
接下来展开讲一讲平台 api 自带的东西是如何进行数据搜集的。
在这之前,得先了解一下应用是如何对外界做出响应的。
响应过程主要牵扯到两个线程,一个是大名鼎鼎的 UI 线程,另一个则是对应用开发者相对透明的渲染线程(RenderThread)。
surfaceflinger 会向应用程序发出 vsync-app 信号,应用在收到这一信号后即要进行下列的工作:
- (UI 线程) 处理输入事件(如屏幕滑动)(外加使得下一步中牵扯到的组件发生改变,于是就响应起来了)。
- (UI 线程) 遍历 View 树,调用相关组件的
draw(),并记录产生的绘制调用(比如“在(0,0)画个圆”)。 - (UI 线程) 为正在进行的动画记录所需的绘制调用。
- (UI 线程) ......
- (UI 线程) 递交所记录的绘制调用给渲染线程。
- (渲染线程) 整理、优化绘制调用。
- (渲染线程) 递交绘制调用给 GPU 。
- (渲染线程) 递交 Graphic Buffer 给 surfaceflinger(1)。
需要注意的是,上面的这一整套过程都已经被包含在了平台 api 中,需要应用开发者开发的,往往只是这个过程中牵扯到的一些回调,比如 onTouchEvent() 和 onDraw() 。
总的来说,UI 线程负责产生绘制调用,渲染线程负责递交绘制调用给 GPU 。
上面这一整套过程需要在一帧(甚至更短)的时间内完成(2),否则就会造成跳帧和卡顿。
我们常说不要在 UI 线程上进行耗时操作,从上面的过程中可以看到,在 UI 线程上进行耗时操作会耽误绘制调用的产生,从而使上面的一整套流程难以在一帧的时间内跑完。
众所周知,普通的 Android 应用可以由 java 和 native 部分组成,平台 api 也是如此,我们可以将上面的这套流程分为 java 和 native 部分:
- (java 层) 处理输入事件(如屏幕滑动)(外加使得下一步中牵扯到的组件发生改变,于是就响应起来了)。
- (java 层) 遍历 View 树,调用相关组件的
draw(),并记录产生的绘制调用(比如“在(0,0)画个圆”)。 - (java 层) 为正在进行的动画记录所需的绘制调用。
- (java 层) ......
- (native 层) 递交所记录的绘制调用给渲染线程。
- (native 层) 整理、优化绘制调用。
- (native 层) 递交绘制调用给 GPU 。
- (native 层) 递交 Graphic Buffer 给 surfaceflinger(1)。
总的来说,java 层的部分用来为应用开发者提供方便的开发接口,native 层则是渲染引擎的主场,这里的 native 部分主要就由 libhwui 负责。
接下来开始正题,现在我们已经了解了应用从收到 vsync 信号到产生帧的大致流程,为了追踪这一整套流程的性能,Android 在平台 api 中埋入了许多“时间采样点”。
以 java 层为例:
frameworks/base/core/java/android/view/Choreographer.java
void doFrame(long frameTimeNanos, int frame,
DisplayEventReceiver.VsyncEventData vsyncEventData) {
......
......
......
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos,
vsyncEventData.preferredFrameTimeline().vsyncId,
vsyncEventData.preferredFrameTimeline().deadline, startNanos,
vsyncEventData.frameInterval);
......
......
mFrameInfo.markInputHandlingStart();
......
mFrameInfo.markAnimationsStart();
......
mFrameInfo.markPerformTraversalsStart();
......
......
}这些“时间采样点”会记录 vsync 信号开始的时间以及那些关键且耗时的流程的发生时间,从而为性能追踪提供依据。
同样的,native 层的 libhwui 渲染库中也有类似的采样点,这里我就只展示头文件中的采样方法了:
frameworks/base/libs/hwui/FrameInfo.h
void markSyncStart() { set(FrameInfoIndex::SyncStart) = systemTime(SYSTEM_TIME_MONOTONIC); }
void markIssueDrawCommandsStart() {
set(FrameInfoIndex::IssueDrawCommandsStart) = systemTime(SYSTEM_TIME_MONOTONIC);
}
void markSwapBuffers() { set(FrameInfoIndex::SwapBuffers) = systemTime(SYSTEM_TIME_MONOTONIC); }
void markSwapBuffersCompleted() {
set(FrameInfoIndex::SwapBuffersCompleted) = systemTime(SYSTEM_TIME_MONOTONIC);
}
void markFrameCompleted() { set(FrameInfoIndex::FrameCompleted) = systemTime(SYSTEM_TIME_MONOTONIC); }这些方法会在渲染管线的关键位置被调用,记录下对应的时间,并为后续的性能追踪提供依据。
注释:
- (1) 此时 GPU 渲染不一定完成了,这里牵扯到 fence ,内容非常复杂,故不再展开了。
- (2) 完成并不一定意味着要产生帧,也不一定需要递交 surfaceflinger ,比如你的应用就是一个静态界面时。这里强调的是没有及时完成一定会跳帧。
数据利用
接下来,就该研究一下该如何利用这些本属于“GPU 呈现模式分析”的数据了。
我们已经知道了,画那幅玄学分析图的逻辑是被做在 native 层 libhwui 的渲染管线中的,而数据采集过程则又同时发生在 java 层和 native 层中。这个过程中有什么弱点吗?或者说,有什么地方比较适合 uprobe 插入断点指令吗?
在 java 层,显然是没有的,这东西牵扯到虚拟机和 JIT ,依托答辩难以下手。
纯的 native 层,好像也没有,它压根就没有保留符号表,找一个函数都费劲。
但是,在 java 层搜集的数据总需要被传递到 native 层吧?毕竟用这些数据画图可发生在 native 层。
诶,这个传递过程总是固定的吧?毕竟 jni call 可是需要固定的符号的。
这就是一个比较简单的下手点。
先来看看 java 层是怎么把数据传递到 native 层的:
frameworks/base/graphics/java/android/graphics/HardwareRenderer.java
/**
* Syncs the RenderNode tree to the render thread and requests a frame to be drawn.
*
* @hide
*/
@SyncAndDrawResult
public int syncAndDrawFrame(@NonNull FrameInfo frameInfo) {
return nSyncAndDrawFrame(mNativeProxy, frameInfo.frameInfo, frameInfo.frameInfo.length);
}这个方法,便是把刚刚采集的数据塞进 native 层的通道。
其中,frameInfo.frameInfo 是一个数组,数组的不同下标代表了不同的数据(比如各个阶段的开始时间),具体定义可参见 FrameInfo.java 。
它调用的 nSyncAndDrawFrame() 是一个 native 方法,不过这个方法并没有作为符号导出,而采用的是动态注册:
frameworks/base/libs/hwui/jni/android_graphics_HardwareRenderer.cpp
static const JNINativeMethod gMethods[] = {
......
{"nSyncAndDrawFrame", "(J[JI)I", (void*)android_view_ThreadedRenderer_syncAndDrawFrame},
......
};
......
int register_android_view_ThreadedRenderer(JNIEnv* env) {
......
return RegisterMethodsOrDie(env, kClassPathName, gMethods, NELEM(gMethods));
}它实际被绑定到的 native 方法是 android_view_ThreadedRenderer_syncAndDrawFrame 。
我们来看看它:
frameworks/base/libs/hwui/jni/android_graphics_HardwareRenderer.cpp
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo,
jint frameInfoSize) {
LOG_ALWAYS_FATAL_IF(frameInfoSize != UI_THREAD_FRAME_INFO_SIZE,
"Mismatched size expectations, given %d expected %zu", frameInfoSize,
UI_THREAD_FRAME_INFO_SIZE);
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
return proxy->syncAndDrawFrame();
}java 层传进来的数组到了 native 层变成了一个 handle ,需要通过调用虚拟机的对应方法来取得数组元素,比如 env->GetLongArrayRegion() 就把数组元素全部 copy 到了 proxy->frameInfo() 。
到了这里,应该能够意识到我们所在的 android_view_ThreadedRenderer_syncAndDrawFrame 是一个非常适合插入 uprobe 断点的方法。
这个方法本身虽然没被作为符号导出,但是注册它时使用的 nSyncAndDrawFrame 是一个常量,那么顺藤摸瓜的找出这个方法的地址应该不成问题。
再看看这个方法的内容,在调用完 env->GetLongArrayRegion() 后,proxy->frameInfo() 不就存储着我们想要的帧数据吗?
那可太棒了,这个方法又好找,又短,又能够方便的获取目标地址,我想应该很难找到一个更完美的 uprobe 对象了。
断点选择
接下来,拿起逆向工具,打开 /system/lib64/libhwui.so ,来确定用于 uprobe 的 offset !
这里以 ida 为例,我们可以直接搜索关键的 nSyncAndDrawFrame ,并找到使用它的地方(注意,不是定义它的地方):

这里,便是我们在上面看到的 gMethods 注册表,而标黄的地方便是目标 android_view_ThreadedRenderer_syncAndDrawFrame 的指针(ida 给它起了个额外的名字)。
双击它,我们可以跳转到 android_view_ThreadedRenderer_syncAndDrawFrame 开始的地方:

(如果你的图是流程图形式,可以按空格切换到这种代码形式)
接下来,我们把汇编对应到上面的原始代码,整理一下这个函数的过程。
首先是红色括号,它所对应的原始代码是 LOG_ALWAYS_FATAL_IF() ,做的是比较和跳转执行,我们不需要管它。
接下来的蓝色括号则是关键部分,它负责为 GetLongArrayRegion() 准备参数。
绿色箭头所指的指令,便是跳转执行 GetLongArrayRegion() 的地方。
橙色部分下面再说。
接下来简单介绍一下 fastcall 函数调用约定:它约定了调用函数时,采用寄存器而不是栈来传递参数(除非参数太多)。
这里的函数调用采用的就是 fastcall 。在 arm64 上,整型参数会被塞进 X 寄存器,比如 this 指针会被塞进 X0 ,第一个参数会被塞进 X1 ,第二个参数被塞进 X2 ,依此类推(前提是参数不要太多)。
可以看到,用来存储帧数据的目标地址 proxy->frameInfo() 是第四个参数,于是在准备参数时,我们最最想要的目标地址将会被放在 X4 寄存器中。
粉色箭头所指向的指令,便把目标地址塞进了 X4 寄存器。
那么,是不是在绿色箭头所指向的指令执行完成后,我们对 X4 寄存器中存储的地址取值,就能够获得帧数据的第一个元素呢?
不对,因为执行绿色箭头所指向的指令,会跳转执行另一个函数,在那个函数中,X4 寄存器的值可能早就被覆盖掉了。
这就意味着,我们需要两个 uprobe 断点才能读取到帧数据。
第一个断点,应该被放在 X4 寄存器赋值之后,即标号为 1 的橙色箭头位置。我们将在此处借助 uprobe 保存 X4 寄存器的值,从而取得存储帧数据的地址。
第二个断点,应该被放在 “跳转执行” 指令之后,即标号为 2 的橙色箭头位置。此时帧数据刚刚被保存到对应地址中,我们需要借助 uprobe 把帧数据取出来。于是,帧生成时间有了,我们就可以进行任何想要的操作了。
你可能会问,为什么是“之后”,而不是就放在那条指令上?那,可以回上面阅读一下 uprobe 的时序。
造好的轮子
https://github.com/libxzr/kernel-playground/commits/playground/hwui_mon
我已经把从操作 uprobe 到计算帧时间的相关逻辑造成了一个轮子,基于 4.19 内核。
你所需要做的,仅仅只是把所需的断点位置以及目标寄存器号填进下面这张表里:
static struct {
......
} hwui_info[] = {
// Here, record info to support different versions of libhwui.so.
#define INFO_COUNT 1
{
.checksum = "dea5f6def7787d5c89fe66e7f888455953fd8880",
.inject1_offset = 0x26868C,
.reg = 4,
.inject2_offset = 0x2686A0
}
};checksum 代表这个 libhwui.so 的 sha1 值,不同机型、不同系统版本的断点位置是很有可能不同的。inject1_offset 代表上面“标号为 1 的橙色箭头”所指指令的文件内偏移。reg 代表那个用来存储目标地址的寄存器号。inject2_offset 代表上面“标号为 2 的橙色箭头”所指指令的文件内偏移。
你大可为不同的系统版本增加不同的信息,记得把上面的 INFO_COUNT 一起改了就行。
这些信息会根据当前 libhwui.so 的 sha1 值进行自动匹配。
接下来讲一讲使用。上面的链接里已经提供了一个 demo:
#include <linux/hwui_mon.h>
#include <linux/module.h>
static void handler(unsigned int ui_frame_time)
{
pr_info("Detect jank in %s with frametime = %d",
current->comm, ui_frame_time);
}
static struct hwui_mon_receiver receiver = {
.jank_frame_time = 4000,
.jank_callback = handler
};
static int __init demo_init(void)
{
return register_hwui_mon(&receiver);
}
module_init(demo_init);注册时需要指定“卡顿时间” jank_frame_time ,只有在“帧生成时间”大于等于“卡顿时间”时,jank_callback 才会被调用。
需要注意的是 jank_callback 运行在应用的 UI 线程上,因此一定不要在其中进行耗时操作,如果有耗时操作请 offload 到 kthreads or workqueues 。
另外,由于它运行在应用进程中,所以你可以使用 current->comm 打印出当前应用的(部分)包名,这对于分应用处理也许会有一些帮助。
帧生成时间?
聪明的你也许已经发现了,我们“帧生成时间”的数据源来自应用进程中 java 层向 native 层传递的数据,这意味着我们得到的所谓“帧生成时间”只是应用在 java 层的耗时,并不完整。
没错,在我们的“帧生成时间”之上,还得加上 native 层渲染引擎的耗时和 GPU 的渲染耗时,才算得上是真正意义上的“帧生成时间”。
但是,不同的应用之间采用的都是相同的 libhwui 库啊,大家跑的 native 渲染引擎代码逻辑是几乎相同的。只要给的绘制调用不是太阴间,native 渲染引擎耗时和 GPU 耗时大家都大差不差。
确实,卡顿主要发生在 java 层的垃圾代码中,这种部分的“帧生成时间”是能够确切反应应用的性能需求的。
但不管怎么样,这都是在找理由,要是完整的“帧生成时间”能轻松拿到,谁还用这个啊(笑
虽然是个妥协,但效果也还不错吧。
因此,你得记住,选择 jank_frame_time 时得为渲染引擎和 GPU 留足余量。比如对 120hz 来说,选择如 4000 us 这样更小的值,而不要卡在 8333 us ,后者即使是掉帧了不一定能够检测出来。
后记
算是比较系统的讲述了一下在内核侧提取帧生成时间的原理以及设计思路,期待你能够在自己的设备上复现上述操作(●'◡'●)
另外,如此获取“帧生成时间”的思路应该还可以通过 Zygisk 实现,只是需要解决一下应用进程与帧时间消费者之间的通信问题(直接用 logcat 也不是不行 xD )
↑ 要是哪天有人做出来了记得给我个 credit 👀
@shadow3 的一个 zygisk 实现
参考资料
https://wizzie.top/Blog/2021/04/14/2021/210414_android_VsyncStudy/
https://www.cnblogs.com/roger-yu/p/16167404.html
https://www.androidperformance.com/2019/12/01/Android-Systrace-Vsync
https://medium.com/@workingkills/understanding-the-renderthread-4dc17bcaf979
https://docs.kernel.org/trace/uprobetracer.html
https://jayce.github.io/public/posts/trace/user-space-probes/
https://gist.github.com/fntlnz/96a6d7bdd9881420c28e6454b8f7b91e
https://github.com/MiCode/Xiaomi_Kernel_OpenSource/blob/317e609aa4fb956c3aff565b62215e5a8041ca0c/kernel/sched/walt/penalty.c#L1042
Xiaomi 14(Pro)的类似实现?
https://github.com/shadow3aaa/frame-analyzer-ebpf rust实现by @shadow3aaa
不错,学习到了
https://developer.android.google.cn/games/optimize/adpf/performance-hint-api?hl=zh-cn
结合aosp源码,设置debug.sf.enable_adpf_cpu_hint为true之后,surfaceflinger会调用lib64/libandroid.so: APerformanceHint_reportActualWorkDuration2发送一个包含gpu渲染时间,cpu渲染时间,总渲染时间等数据的class